hunyuan-large-vision 腾讯混元推出的多模态视觉理解模型
时间:2025-08-16 16:24:52
hunyuan-large-vision 是什么
Hunyuan-large-vision,一款由腾讯研发的先进多模态理解模型,采用了moe(mixture of experts)架构,其激活参数规模达到了,具备处理图像、视频及三维空间数据的能力。在国际权威的大模型评测平台“LMARENA Vision排行榜”中,Hunyuan-large-vision以的成绩位列第五位,是当前国内领先的多模态语言模型之一,展示了其强大的多语言交互能力与用户体验。Hunyuan-large-vision的主要组成部分包括数十亿参数的混元视觉编码器、具备自适应下采样能力的mlp连接模块以及拥有总参数的moe语言模型。通过大量的高质量多模态指令数据训练,该模型在视觉识别和语言理解方面表现出色,广泛应用于拍照解题、视频内容分析及智能文案生成等实际场景中。Hunyuan-large-vision展现了腾讯在人工智能领域的卓越研发能力,为解决复杂多模态信息处理难题提供了有力的技术支持。
AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型
 hunyuan-large-vision 的主要功能
hunyuan-large-vision 的主要功能
图像解析:精准捕捉不同分辨率的图像细节,适用于拍照解题、图像分类和目标检测等任务。视频剖析:能够深入理解视频内容,生成摘要,并支持实时通话辅助等应用。多语言交流:多种语言输入与输出能力,有效提高跨语言理解和翻译水平。三维空间感知:处理三维空间信息,实现对复杂场景的精准分析与描绘。文案创作:自动根据视觉元素生成描述性文本或创意文章,助力内容创作效率大幅提升。
hunyuan-large-vision 的技术原理
先进的图像编码器(混元ViT):利用数十亿参数构建的ViT架构,支持原生分辨率图像输入,显著提升图像和视频中的深层视觉特征提取效率。引入的MLP连接器模块采用自适应下采样机制,有效优化了视觉特征的压缩与对齐,实现了图像与语言模块之间的高效融合。此外,该模型还具备强大的生成能力,通过参数激活激活参数,支持多种语言的高质量语言生成和推理。高质量多模态指令数据集:包含超过 tokens的多模态指令样本,涵盖视觉、数学、科学等多个领域,显著提升模型在不同领域的泛化能力和稳定性。同时,拒绝采样微调技术通过过滤错误和低质量样本,进一步提升了模型的推理准确性与多语言稳定性。知识蒸馏技术:从长思维链大模型中汲取知识,优化了短链推理表现,增强复杂任务处理能力。通过这些创新技术的应用,视觉编码器(混元ViT)不仅在图像与视频特征提取方面表现出色,还在多模态指令生成和语言理解上实现了突破性的进展。
hunyuan-large-vision 的项目地址
项目官网:https://www.php.cn/link/2fecdeaa123ef60a82894a45c5a7ae26
hunyuan-large-vision 的应用场景
拍照解题:学生通过拍照上传习题,AI自动识别人物与环境细节,提供详细解答或建议。视频字幕生成:为多语种视频内容自动生成配套字幕,增强跨语言交流的便捷性。多语言文案创作:利用图像识别技术生成多种语言的文本描述,适用于国际化推广策略。虚拟现实(VR)与增强现实(AR):在VR/AR环境中准确呈现三维物体和环境细节,提供直观操作指引。智能客服:用户上传产品使用问题图片,AI检测并推荐解决方案,提高服务效率与用户体验。
以上就是hunyuan-large-vision 腾讯混元推出的多模态视觉理解模型的详细内容,更多请关注其它相关文章!
热门推荐
-
 腾讯会议电脑手机怎么同时在线_腾讯会议电脑手机可以同时用吗腾讯会议电脑手机怎么同时在线?为了能够去更为便利的运用,得多的小伙伴都会去抉择在手机和电脑端来一块儿运用腾讯集会,那腾讯集会电脑手机能够同时在线吗?一块儿来看看吧~
腾讯会议电脑手机怎么同时在线_腾讯会议电脑手机可以同时用吗腾讯会议电脑手机怎么同时在线?为了能够去更为便利的运用,得多的小伙伴都会去抉择在手机和电脑端来一块儿运用腾讯集会,那腾讯集会电脑手机能够同时在线吗?一块儿来看看吧~ -
 腾讯游戏安全知识答题答案最新-2025腾讯游戏的安全知识答题腾讯游戏的安全知识答题你能全部答对吗,有时候系统根据用户的使用情况,如果有操作异常等现象,腾讯会相应的封号,用户只能进行答题解封,下面就是小编为大家整理的2022腾讯游戏的安全知识答题,一起来看看吧
腾讯游戏安全知识答题答案最新-2025腾讯游戏的安全知识答题腾讯游戏的安全知识答题你能全部答对吗,有时候系统根据用户的使用情况,如果有操作异常等现象,腾讯会相应的封号,用户只能进行答题解封,下面就是小编为大家整理的2022腾讯游戏的安全知识答题,一起来看看吧 -
 可否同时参加两个腾讯会议_一个号可以同时进两个腾讯会议吗可否同时参加两个腾讯会议?根据我们的身份和职能不同,有时候我们可能要同时参加多个会议,线下会议场地不同,一般是无法做到的,但线上会议却可以,很多用户不知道一个号怎么进入两个腾讯会议,一起来看看吧
可否同时参加两个腾讯会议_一个号可以同时进两个腾讯会议吗可否同时参加两个腾讯会议?根据我们的身份和职能不同,有时候我们可能要同时参加多个会议,线下会议场地不同,一般是无法做到的,但线上会议却可以,很多用户不知道一个号怎么进入两个腾讯会议,一起来看看吧 -
 腾讯游戏安全中心10道题答案2023有的玩家的游戏账号呈现的特别很是问题,必要返回腾讯游戏安宁焦点进行答题请求解封。这边小编就为网友带来了腾讯游戏安宁焦点10道题谜底2023,游戏安宁知识答题谜底2023最新版,帮助网友告捷供应正确谜底,回复全盘的题目。
腾讯游戏安全中心10道题答案2023有的玩家的游戏账号呈现的特别很是问题,必要返回腾讯游戏安宁焦点进行答题请求解封。这边小编就为网友带来了腾讯游戏安宁焦点10道题谜底2023,游戏安宁知识答题谜底2023最新版,帮助网友告捷供应正确谜底,回复全盘的题目。 -
 hunyuan-large-vision 腾讯混元推出的多模态视觉理解模型hunyuan-large-vision是什么Hunyuan-large-vision,一款由腾讯研发的先进多模态理解模型,采用了moe(mixtureofexp
hunyuan-large-vision 腾讯混元推出的多模态视觉理解模型hunyuan-large-vision是什么Hunyuan-large-vision,一款由腾讯研发的先进多模态理解模型,采用了moe(mixtureofexp -
 混元3D世界模型 1.0 腾讯开源的3D世界生成模型混元3D世界模型1.是什么腾讯在世界人工智能大会上正式推出的全球首个支持沉浸式漫游、交互与仿真的混元世界模型hunyuanworld是其创新性成果之一
混元3D世界模型 1.0 腾讯开源的3D世界生成模型混元3D世界模型1.是什么腾讯在世界人工智能大会上正式推出的全球首个支持沉浸式漫游、交互与仿真的混元世界模型hunyuanworld是其创新性成果之一 -
 德国改装厂 Irmscher 将联手零跑推出高性能版 C10:双电机四驱 585 马力消息,据德国AutoMotorSport报道,总部位于斯图加特附近雷姆沙尔登的改装厂Irmscher与全球多家品牌,包括中国的零跑,都曾有过合作
德国改装厂 Irmscher 将联手零跑推出高性能版 C10:双电机四驱 585 马力消息,据德国AutoMotorSport报道,总部位于斯图加特附近雷姆沙尔登的改装厂Irmscher与全球多家品牌,包括中国的零跑,都曾有过合作 -
 乐道推出 L90 等车积分:若 28 天内未能提车,次日起每天送 500 积分,乐道汽车通过其官方App宣布了当前生产准备及供应链协调的进展,并表示尽管已尽全力提高产量并加快发货速度,但部分订单交付时间仍会比原定计划稍长
乐道推出 L90 等车积分:若 28 天内未能提车,次日起每天送 500 积分,乐道汽车通过其官方App宣布了当前生产准备及供应链协调的进展,并表示尽管已尽全力提高产量并加快发货速度,但部分订单交付时间仍会比原定计划稍长 -
 《海贼无双4》全新DLC宣传片 推出“角色通行证3”!近日,发行商Banpresto和开发商OmegaOmegaForce宣布将推出海贼无双新DLC“角色通行证(CharacterPass,其中包括六位可玩角色,并分
《海贼无双4》全新DLC宣传片 推出“角色通行证3”!近日,发行商Banpresto和开发商OmegaOmegaForce宣布将推出海贼无双新DLC“角色通行证(CharacterPass,其中包括六位可玩角色,并分 -
 3 组原生 12V-2×6 模组接口,威刚 XPG 推出 PYMCORE SFX 金牌小尺寸电源近日,威刚在台北国际电脑展(COMPUTEXTaipei上展示了全新的XPGPYMCORE系列全模组电源解决方案
3 组原生 12V-2×6 模组接口,威刚 XPG 推出 PYMCORE SFX 金牌小尺寸电源近日,威刚在台北国际电脑展(COMPUTEXTaipei上展示了全新的XPGPYMCORE系列全模组电源解决方案 -
 多模态AI如何识别微观流体运动 多模态AI流体动力学可视化多模态AI在微观流体运动的识别中发挥了核心作用,它依赖于多种数据源以提升准确性。多模态数据采集包括高速显微成像、激光测速(LDV/PIV)、热传感器和压力传感器反
多模态AI如何识别微观流体运动 多模态AI流体动力学可视化多模态AI在微观流体运动的识别中发挥了核心作用,它依赖于多种数据源以提升准确性。多模态数据采集包括高速显微成像、激光测速(LDV/PIV)、热传感器和压力传感器反 -
 多模态AI如何优化图像识别速度 多模态AI推理性能调优技巧提升图像识别速度的关键在于多模态融合策略及性能调优。多模态融合策略通过引入文本、音频等额外信息,帮助模型快速排除干扰并提高决策置信度,其中早期融合整合原始数据但易
多模态AI如何优化图像识别速度 多模态AI推理性能调优技巧提升图像识别速度的关键在于多模态融合策略及性能调优。多模态融合策略通过引入文本、音频等额外信息,帮助模型快速排除干扰并提高决策置信度,其中早期融合整合原始数据但易 -
 多模态AI如何识别显微图像 多模态AI细胞结构分析方案在显微图像识别领域,多模态人工智能(MultimodalAI)的作用是通过整合多种数据形式来提升识别准确性
多模态AI如何识别显微图像 多模态AI细胞结构分析方案在显微图像识别领域,多模态人工智能(MultimodalAI)的作用是通过整合多种数据形式来提升识别准确性 -
 Intern-S1 上海AI Lab推出的科学多模态大模型Intern-S1是什么新型科学多模态模型Intern-S式开源在上海人工智能大会上,由上海人工智能实验室推出的Intern-S为关注焦点
Intern-S1 上海AI Lab推出的科学多模态大模型Intern-S1是什么新型科学多模态模型Intern-S式开源在上海人工智能大会上,由上海人工智能实验室推出的Intern-S为关注焦点 -
 掌握 Deepseek 满血版与 Flair AI Pro,打造专属品牌视觉deepseek满血版和flairaipro都是强大的工具,适用于快速打造有辨识度的品牌视觉。首先,deepseek满血版能够完美地优化关键词、保持风格统一,并快
掌握 Deepseek 满血版与 Flair AI Pro,打造专属品牌视觉deepseek满血版和flairaipro都是强大的工具,适用于快速打造有辨识度的品牌视觉。首先,deepseek满血版能够完美地优化关键词、保持风格统一,并快 -
 PS5 Pro推动视觉保真度 助力《异形》新作画面提升异形:外星入侵的第一部分已在推出PlayStationVRMetaQuestPCVR硬件,而游戏的非VR版本“进化版”将于今年在PSPC平台上市
PS5 Pro推动视觉保真度 助力《异形》新作画面提升异形:外星入侵的第一部分已在推出PlayStationVRMetaQuestPCVR硬件,而游戏的非VR版本“进化版”将于今年在PSPC平台上市 -
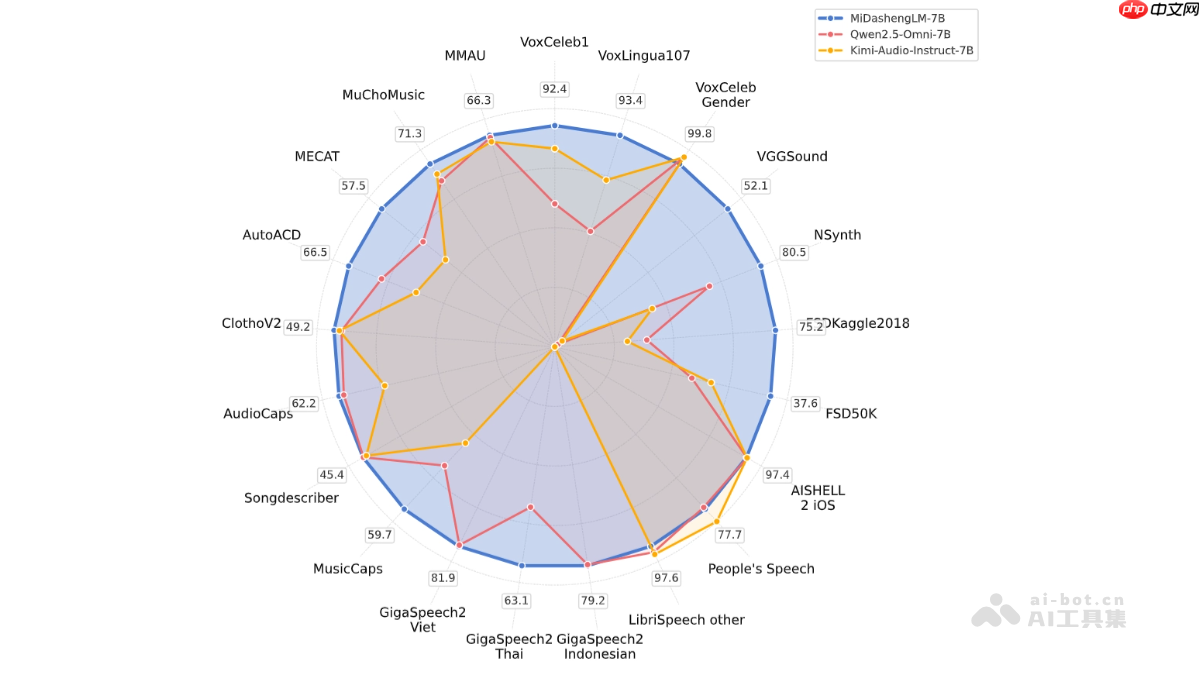 MiDashengLM 小米开源的高效声音理解大模型MiDashengLM是什么小米推出了一款高效的音频理解大模型:midashenglm-。这款模型是由xiaomidasheng音频编码器和qwenomni-th
MiDashengLM 小米开源的高效声音理解大模型MiDashengLM是什么小米推出了一款高效的音频理解大模型:midashenglm-。这款模型是由xiaomidasheng音频编码器和qwenomni-th -
 小米声音理解大模型 MiDashengLM-7B 发布并全量开源,22 个公开评测集刷新最好成绩xiayx8月4日消息,小米自研声音理解大模型MiDashengLM-7B今日正式发布,并全量开源。据小米官方介绍,MiDashengLM-在速度与精度方面实现了
小米声音理解大模型 MiDashengLM-7B 发布并全量开源,22 个公开评测集刷新最好成绩xiayx8月4日消息,小米自研声音理解大模型MiDashengLM-7B今日正式发布,并全量开源。据小米官方介绍,MiDashengLM-在速度与精度方面实现了 -
 Perplexity AI如何实现语义理解 Perplexity AI上下文关联分析本文将深入探讨PerplexityAI在实现语义理解和上下文关联分析方面的能力。我们将解析其核心技术,并逐步介绍PerplexityAI如何通过多维度数据分析,有
Perplexity AI如何实现语义理解 Perplexity AI上下文关联分析本文将深入探讨PerplexityAI在实现语义理解和上下文关联分析方面的能力。我们将解析其核心技术,并逐步介绍PerplexityAI如何通过多维度数据分析,有 -
 多模态AI如何处理图像描述任务 图像理解与文字生成技术说明在当今数字时代,多模态人工智能(MMA)系统已经显示出其强大的能力,能够处理和理解复杂的数据类型。其中一个令人瞩目的应用是图像理解和文字生成任务
多模态AI如何处理图像描述任务 图像理解与文字生成技术说明在当今数字时代,多模态人工智能(MMA)系统已经显示出其强大的能力,能够处理和理解复杂的数据类型。其中一个令人瞩目的应用是图像理解和文字生成任务 -
 腾讯元宝如何搭载满血DeepSeekR1模型腾讯元宝:搭载满血deepseekr1模型,重塑智能新体验在当今科技迅猛发展的时代,人工智能已经深入渗透到我们生活的各个角落,从智能家居到智能出行,再到智能助手,
腾讯元宝如何搭载满血DeepSeekR1模型腾讯元宝:搭载满血deepseekr1模型,重塑智能新体验在当今科技迅猛发展的时代,人工智能已经深入渗透到我们生活的各个角落,从智能家居到智能出行,再到智能助手, -
 DeepSeek如何配置模型蒸馏 DeepSeek知识迁移训练方案本文深入探讨了如何利用DeepSeek模型进行知识蒸馏,并提供了一套实用的训练方案,帮助用户轻松掌握这一过程
DeepSeek如何配置模型蒸馏 DeepSeek知识迁移训练方案本文深入探讨了如何利用DeepSeek模型进行知识蒸馏,并提供了一套实用的训练方案,帮助用户轻松掌握这一过程 -
 豆包 AI 大模型怎样和 AI 模型角色设计工具结合设计角色?攻略豆包AI大模型与角色设计工具的结合,实现了高效的角色创作。具体步骤如下:使用豆包生成角色背景故事,提供关键词进行优化;应用角色设计工具调整外貌、服装等参数,并上传
豆包 AI 大模型怎样和 AI 模型角色设计工具结合设计角色?攻略豆包AI大模型与角色设计工具的结合,实现了高效的角色创作。具体步骤如下:使用豆包生成角色背景故事,提供关键词进行优化;应用角色设计工具调整外貌、服装等参数,并上传 -
 Qwen-Flash 阿里通义推出的Qwen3系列高性能模型Qwen-Flash是什么Qwen-Flash:阿里巴巴通义实验室最新推出的小型化高性能模型最近,阿里巴巴通义实验室推出了一个名为Qwen的新型机器学习模型,这是
Qwen-Flash 阿里通义推出的Qwen3系列高性能模型Qwen-Flash是什么Qwen-Flash:阿里巴巴通义实验室最新推出的小型化高性能模型最近,阿里巴巴通义实验室推出了一个名为Qwen的新型机器学习模型,这是