DeepSeek如何配置模型蒸馏 DeepSeek知识迁移训练方案
时间:2025-08-14 12:48:20
本文深入探讨了如何利用DeepSeek模型进行知识蒸馏,并提供了一套实用的训练方案,帮助用户轻松掌握这一过程。通过详细的讲解和一步步的指导,您可以有效地将大型DeepSeek模型的知识迁移到更小的模型中,从而实现更快的推理和部署。

理解模型蒸馏
模型蒸馏是一种压缩技术,核心在于训练一个较小“学生”模型以模仿大型“教师”模型的表现。通过学习教师输出的概率分布(软目标)以及自身硬目标,学生能高效掌握教师知识,保持高精度的同时显著减小体积和加速推理速度。
DeepSeek模型蒸馏的准备工作
在开始蒸馏过程之前,需要进行一些准备工作,以确保顺利进行。
定选“教师”模型:挑选高性能但体型庞大的DeepSeek教师模型进行蒸馏。
首先选定目标学生成型:选取简化版学生成本模型,需小于教师模并契合预算要求资源!
准备数据集:创建包含与您任务相关而未标记的数据集,以让学生模型模仿教师模型的输出分布。
DeepSeek知识迁移训练方案
本方案将指导您如何一步步地配置和执行DeepSeek模型的知识蒸馏训练。

第一阶段:教师模型的准备
加载预训练的DeepSeek教师模型,确保高质量并满足任务要求。
- 将教师模型设置为评估模式(evaluation mode),以禁用任何与训练相关的特定行为(如dropout)。
第二阶段:学生模型的配置
- 初始化一个与教师模型结构相似但参数量更小的学生模型。
定义一个损失函数。通常,蒸馏损失包含两部分:一是学生模型在硬目标上的交叉熵损失(如标准的监督学习损失),二是学生模型输出的概率分布与教师模型输出的概率分布之间的KL散度损失(用以学习软目标)。
- 设置优化器,例如AdamW,并配置学习率和学习率调度器。
第三阶段:蒸馏训练过程
- 迭代遍历准备好的无标签数据集。
- 对于数据集中的每个样本:
a. 将样本输入到教师模型中,获取其输出概率分布(软目标)。
b. 将样本输入到学生模型中,获取其输出概率分布。
c. 计算蒸馏损失:考虑学生模型在硬目标上的误差,以及学生模型与教师模型软目标间的KL散度损失。常设有权重调节两者损失的比例。
d. 反向传播计算梯度,并使用优化器更新学生模型的参数。
- 定期评估学生模型在验证集上的性能,以监控训练进展和防止过拟合。
- 训练直到学生模型在验证集上达到预期的性能水平或达到预设的训练轮数。

关键参数调整
在蒸馏过程中,一些参数的调整对于获得良好的蒸馏效果至关重要。
新版在计算软目标时,通常采用一个温度参数以平滑概率分布。较高温度下的分布更加平滑,有助于保留更多教师模型的信息。
2. 蒸馏损失权重: 调整软目标损失和硬目标损失之间的权重,以达到最佳的知识迁移效果。
3. 学习率: 合理的学习率对于学生模型的收敛至关重要。建议从较小的学习率开始,并逐步调整。
掌握深度学习技巧后,只需精细调节参数,即可成功应用DeepSeek模型进行知识迁移,从而建立高性能的学生模型。
以上就是DeepSeek如何配置模型蒸馏 DeepSeek知识迁移训练方案的详细内容,更多请关注其它相关文章!
热门推荐
-
 华为手机上传到中转站怎么关闭 华为手机如何关闭上传到中转站华为手机如何关闭上传到中转站:对于华为手机不少用户都在使用啦,当然这可手机功能也是非常强大的。对于这款世界如何关闭上传到中转站呢?小编为玩家整理了相关内容,下面一起来看看相关的信息。
华为手机上传到中转站怎么关闭 华为手机如何关闭上传到中转站华为手机如何关闭上传到中转站:对于华为手机不少用户都在使用啦,当然这可手机功能也是非常强大的。对于这款世界如何关闭上传到中转站呢?小编为玩家整理了相关内容,下面一起来看看相关的信息。 -
 三国志11威力加强版庙和遗迹如何触发 三国志11庙和遗迹坐标位置机制详解三国志11威力加强版庙和遗迹如何触发:在三国志11游戏中很多玩法还是挺多的,对于游戏中庙和遗迹我们又该如何触发呢?想必不少玩家还是不了解的,小编整理了三国志11庙和遗迹机制详解,下面一起来看看相关的信息。
三国志11威力加强版庙和遗迹如何触发 三国志11庙和遗迹坐标位置机制详解三国志11威力加强版庙和遗迹如何触发:在三国志11游戏中很多玩法还是挺多的,对于游戏中庙和遗迹我们又该如何触发呢?想必不少玩家还是不了解的,小编整理了三国志11庙和遗迹机制详解,下面一起来看看相关的信息。 -
 学习通如何查看学号工号_学习通查看学号工号方法介绍学习通查看学号工号方法介绍:对于学习通这款软件功能还是挺多的,在这款软件想要查询工号又该如何搞呢?这也是很多用户不了解的,在这里为用户整理了学习通查看工号学号方法介绍,下面一起来看看相关的信息。
学习通如何查看学号工号_学习通查看学号工号方法介绍学习通查看学号工号方法介绍:对于学习通这款软件功能还是挺多的,在这款软件想要查询工号又该如何搞呢?这也是很多用户不了解的,在这里为用户整理了学习通查看工号学号方法介绍,下面一起来看看相关的信息。 -
 学习通如何添加好友_学习通添加好友方法教程学习通添加好友方法教程:在学习通这款软件功能还是挺多的,对于这款软件想和别人聊天又该如何搞呢?这也是很多玩家不了解的,小编整理了学习通添加好友方法介绍,下面一起来看看相关的信息。
学习通如何添加好友_学习通添加好友方法教程学习通添加好友方法教程:在学习通这款软件功能还是挺多的,对于这款软件想和别人聊天又该如何搞呢?这也是很多玩家不了解的,小编整理了学习通添加好友方法介绍,下面一起来看看相关的信息。 -
 uc浏览器收藏如何设置密码_uc浏览器隐私收藏设置方法介绍uc浏览器收藏如何设置密码:对于uc浏览器这款软件想必很多用户都在使用,当然在这款软件隐私收藏如何加密呢?想必很多玩家还是不了解的,小编整理了相关内容介绍,下面一起来看看相关的信息。
uc浏览器收藏如何设置密码_uc浏览器隐私收藏设置方法介绍uc浏览器收藏如何设置密码:对于uc浏览器这款软件想必很多用户都在使用,当然在这款软件隐私收藏如何加密呢?想必很多玩家还是不了解的,小编整理了相关内容介绍,下面一起来看看相关的信息。 -
 Hinova9SE是华为手机吗-hinova9se配置参数处理器Hi nova 9 SE是华为手机吗?这款手机是5G手机,但是华为旗舰机手机也没有支持5G,很多网友想知道Hi nova 9 SE手机和华为什么关系,一起来看看吧
Hinova9SE是华为手机吗-hinova9se配置参数处理器Hi nova 9 SE是华为手机吗?这款手机是5G手机,但是华为旗舰机手机也没有支持5G,很多网友想知道Hi nova 9 SE手机和华为什么关系,一起来看看吧 -
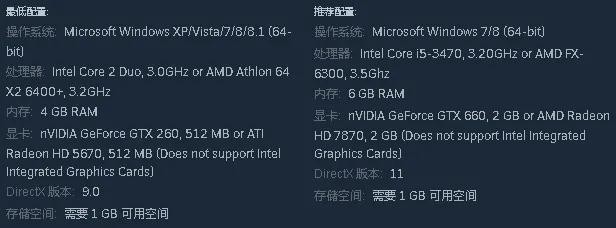 都市天际线电脑配置推荐城市:天涯线,这款游戏在steam平台、EPIC平台以及某宝都可以买到,游戏本体原价是88元(又有好多免费和付费的DLC后头会给大伙讲),每个平台偶然会打折乃至免
都市天际线电脑配置推荐城市:天涯线,这款游戏在steam平台、EPIC平台以及某宝都可以买到,游戏本体原价是88元(又有好多免费和付费的DLC后头会给大伙讲),每个平台偶然会打折乃至免 -
 ensp怎么保存配置(ensp 保存)1、配置好了一些命令。首先我们要退出用户模式。命令是quit。 2、退出用户模式后输入save。 3、在弹出的输入一行中写一个y,表示yes. 4、等待几秒就可以看到保存成功了。 5、然后我们将配置文件导出。右击
ensp怎么保存配置(ensp 保存)1、配置好了一些命令。首先我们要退出用户模式。命令是quit。 2、退出用户模式后输入save。 3、在弹出的输入一行中写一个y,表示yes. 4、等待几秒就可以看到保存成功了。 5、然后我们将配置文件导出。右击 -
华为Mate40E的参数配置详情,这款手机有着怎么样的性能配置今日,有外媒曝光了关于华为Mate40E的信息,接下来小编就为大家带来了,华为Mate40E的参数配
-
 华为mya-al10什么型号 华为mya-al10配置信息华为mya-al10的手机型号是华为荣耀畅玩6全网通版,是一部性价比比较高的手机。
华为mya-al10什么型号 华为mya-al10配置信息华为mya-al10的手机型号是华为荣耀畅玩6全网通版,是一部性价比比较高的手机。 -
DeepSeek如何配置模型蒸馏 DeepSeek知识迁移训练方案本文深入探讨了如何利用DeepSeek模型进行知识蒸馏,并提供了一套实用的训练方案,帮助用户轻松掌握这一过程
-
 豆包 AI 大模型怎样和 AI 模型角色设计工具结合设计角色?攻略豆包AI大模型与角色设计工具的结合,实现了高效的角色创作。具体步骤如下:使用豆包生成角色背景故事,提供关键词进行优化;应用角色设计工具调整外貌、服装等参数,并上传
豆包 AI 大模型怎样和 AI 模型角色设计工具结合设计角色?攻略豆包AI大模型与角色设计工具的结合,实现了高效的角色创作。具体步骤如下:使用豆包生成角色背景故事,提供关键词进行优化;应用角色设计工具调整外貌、服装等参数,并上传 -
 Qwen-Flash 阿里通义推出的Qwen3系列高性能模型Qwen-Flash是什么Qwen-Flash:阿里巴巴通义实验室最新推出的小型化高性能模型最近,阿里巴巴通义实验室推出了一个名为Qwen的新型机器学习模型,这是
Qwen-Flash 阿里通义推出的Qwen3系列高性能模型Qwen-Flash是什么Qwen-Flash:阿里巴巴通义实验室最新推出的小型化高性能模型最近,阿里巴巴通义实验室推出了一个名为Qwen的新型机器学习模型,这是 -
微软将 OpenAI 最小开源模型 gpt-oss-20b 引入 Windows,本地也能跑,微软宣布借助WindowsAIFoundry平台向Windows户提供OpenAI最新推出的免费开源大模型GPT-OSS-
-
 DeepSeek如何配置模型监控 DeepSeek性能指标可视化方案本文将探讨如何配置模型监控以及使用DeepSeek进行性能指标可视化的方法。我们将详细说明设置监控所需的操作,并提供一系列实用建议,帮助您全面掌握并优化DeepS
DeepSeek如何配置模型监控 DeepSeek性能指标可视化方案本文将探讨如何配置模型监控以及使用DeepSeek进行性能指标可视化的方法。我们将详细说明设置监控所需的操作,并提供一系列实用建议,帮助您全面掌握并优化DeepS -
 《杀戮空间3》新手局内局外小知识分享杀戮空间于新手来说并非易上手的游戏,他们可能需要注意以下几点:首先,力量伤害是唯一的无弱点影响的优质特性;其次,酸性和热能伤害都会引发对方的混乱
《杀戮空间3》新手局内局外小知识分享杀戮空间于新手来说并非易上手的游戏,他们可能需要注意以下几点:首先,力量伤害是唯一的无弱点影响的优质特性;其次,酸性和热能伤害都会引发对方的混乱 -
 AI Overviews如何设置知识图谱 AI Overviews语义关系挖掘为了让AIOverviews提供更精准、丰富的摘要和回答,构建高质量的知识图谱并挖掘其中的语义关系至关重要
AI Overviews如何设置知识图谱 AI Overviews语义关系挖掘为了让AIOverviews提供更精准、丰富的摘要和回答,构建高质量的知识图谱并挖掘其中的语义关系至关重要 -
 2025支付宝庄园小课堂今日答案8.10_睡眠小知识:下雨天更有助于睡眠,真的吗2025支付宝庄园小课堂今日答案8.10:庄园小课堂今天答题更新了,玩家参与答题也能获得饲料奖励。小编整理了庄园小课堂8月10日答题睡眠小知识:下雨天更有助于睡眠,真的吗?下面一起来看看相关的信息。
2025支付宝庄园小课堂今日答案8.10_睡眠小知识:下雨天更有助于睡眠,真的吗2025支付宝庄园小课堂今日答案8.10:庄园小课堂今天答题更新了,玩家参与答题也能获得饲料奖励。小编整理了庄园小课堂8月10日答题睡眠小知识:下雨天更有助于睡眠,真的吗?下面一起来看看相关的信息。 -
 王者荣耀安卓迁移ios多少钱 安卓转IOS所需成本一览众所周知,王者荣耀的账号数据可以通过王者营地App进行转移,不过跨区服务是要收费的。那么就有召唤师会问:王者荣耀安卓迁移ios多少钱呢?本期就来回答这个问题,快来了解一番吧!
王者荣耀安卓迁移ios多少钱 安卓转IOS所需成本一览众所周知,王者荣耀的账号数据可以通过王者营地App进行转移,不过跨区服务是要收费的。那么就有召唤师会问:王者荣耀安卓迁移ios多少钱呢?本期就来回答这个问题,快来了解一番吧! -
 企业微信怎么把微信群迁移过来企业微信把微信群迁移过来共分为三步,只需要找到接收微信中的工作消息入口即可操作。具体步骤如下:
企业微信怎么把微信群迁移过来企业微信把微信群迁移过来共分为三步,只需要找到接收微信中的工作消息入口即可操作。具体步骤如下: -
 马斯克宣布特斯拉正训练新 FSD 模型:约十倍参数,最快下月底发布xiayx8月6日消息,马斯克今日在X上发文表示,特斯拉正在训练新的十倍参数FSD模型,如果一切顺利则可能会在下个月底准备好面向公众发布
马斯克宣布特斯拉正训练新 FSD 模型:约十倍参数,最快下月底发布xiayx8月6日消息,马斯克今日在X上发文表示,特斯拉正在训练新的十倍参数FSD模型,如果一切顺利则可能会在下个月底准备好面向公众发布 -
 黄仁勋:华为芯片在 AI 训练中取代英伟达只是时间问题月日消息,据第一财经报道,英伟达CEO黄仁勋近日在接受媒体采访时表示,在AI训练过程中,华为的AI芯片可能会在短期内取代英伟达产品,但这是一个逐渐的过程
黄仁勋:华为芯片在 AI 训练中取代英伟达只是时间问题月日消息,据第一财经报道,英伟达CEO黄仁勋近日在接受媒体采访时表示,在AI训练过程中,华为的AI芯片可能会在短期内取代英伟达产品,但这是一个逐渐的过程 -
 DeepSeek如何实现模型增量训练 DeepSeek持续学习配置指南本文旨在阐述DeepSeek模型如何实现增量训练,即在已有模型基础上利用新数据进行持续学习。增量训练是使模型适应新知识或特定领域变化的重要手段
DeepSeek如何实现模型增量训练 DeepSeek持续学习配置指南本文旨在阐述DeepSeek模型如何实现增量训练,即在已有模型基础上利用新数据进行持续学习。增量训练是使模型适应新知识或特定领域变化的重要手段 -
 如何使用BigDL训练AI模型 BigDL分布式深度学习框架入门bigdl是一个基于ApacheSpark的分布式深度学习框架,非常适合熟悉Spark或需在大数据环境下进行深度学习的人群
如何使用BigDL训练AI模型 BigDL分布式深度学习框架入门bigdl是一个基于ApacheSpark的分布式深度学习框架,非常适合熟悉Spark或需在大数据环境下进行深度学习的人群 -
 cf手游小镇怎么加点 最佳加点方案是什么穿越火线(CF)手游中的小镇地图,其独特的地形和策略性使其成为比赛的重要元素之一。正确的加点技巧不仅有助于提升个人技能,还能增强团队协作能力,使你在紧张刺激的对战
cf手游小镇怎么加点 最佳加点方案是什么穿越火线(CF)手游中的小镇地图,其独特的地形和策略性使其成为比赛的重要元素之一。正确的加点技巧不仅有助于提升个人技能,还能增强团队协作能力,使你在紧张刺激的对战 -
 七日世界隐秘行者罩衫如何搭配 七日世界隐秘行者罩衫配装方案在噩梦收容井的挑战中,合理选择装备是提升战斗力的关键,所以你需要了解和掌握这种技巧。七日世界中的隐秘行者罩衫是一种独特的道具,但它应该如何搭配却是一个值得探索的问
七日世界隐秘行者罩衫如何搭配 七日世界隐秘行者罩衫配装方案在噩梦收容井的挑战中,合理选择装备是提升战斗力的关键,所以你需要了解和掌握这种技巧。七日世界中的隐秘行者罩衫是一种独特的道具,但它应该如何搭配却是一个值得探索的问 -
 《三角洲行动》S4赛季SKS射手步枪高改方案三角洲行动S季SKS射击手怎么调整枪支?SKS射手步枪曾经是游戏中的王者,在削弱后很多人都忘记了它。在S季中,这把强大的武器重新焕发了活力,再次占据了前十位的位置
《三角洲行动》S4赛季SKS射手步枪高改方案三角洲行动S季SKS射击手怎么调整枪支?SKS射手步枪曾经是游戏中的王者,在削弱后很多人都忘记了它。在S季中,这把强大的武器重新焕发了活力,再次占据了前十位的位置 -
梦幻西游五开阵容全攻略 高/中/低投入搭配方案解析本站网为您带来225年最新梦幻西游五开阵容搭配深度解析。本文将从高投入、中等投入及低投入三大维度,系统梳理五开玩法的核心策略
-
方案复制教程 和平精英灵敏度推荐码在哪里用和平精英海岛新后,上线了灵敏度的分享功能,特种兵之间可以通过分享码使用各自的灵敏度方案。但是需要注意的是,这个功能在设置界面底部实现,在使用前要确认分辨率相同