【Tutorial】一文学会在AIStudio上部署Deepseek-R1
时间:2025-08-08 12:38:58
该项目总结了AIStudio上主流的DeepSeek-R用方式,省去了开发者需要进行调研的工作,从而加速平台项目的繁荣发展。以下是四种方法介绍:星河大模型API服务、一键部署到星河社区(对于非GPU环境推荐)、本地部署使用Ollama和PaddleNLP GPU环境优先)。详细的操作步骤包括从GitHub fork项目,选择合适的工作环境进行运行,从而充分发挥创造力。

一、项目背景
自从发布超过一个月以来,DeepSeek-R经登顶了大型模型榜单,并且在AIStuido平台上涌现了许多与之相关的热门项目。
根据我的个人研究发现,在AIStudio平台上进行项目的开发时,大多数情况下是将DeepSeek-R署到环境之中使用。方法包括通过Ollama部署、PaddleNLP调用以及部分项目会调用ModelBuilder中的DeepSeek-RAPI接口等。这些方式各有特点,但最终目的都是为了更好地利用和扩展AIStudio的资源和服务。
本项目简化了DeepSeek-R调用,减少开发者的探索成本,促进AIStudio生态健康发展。
立即启动探索之旅!通过fork并从选定环境中启动该项目。将当前查看的IPython Notebook改名为你钟爱的深海探寻者(DeepSeek)。灵活选择合适的框架部署模型。创建一个新的主页面项目,在这里尽情展现你的创意!
环境选择(必看)
本项目介绍的四种方法,推荐二、星河大模型 API 服务与三、星河社区一键部署。不需 GPU 环境。
其余的两种环境推荐使用GPU环境,V100或A100都可以,显存大小不做要求。
二、星河大模型 API 服务(推荐)
点击这里前往星河大模型 API 服务
是的,星河大模型 API 服务支持DeepSeek-R1了!
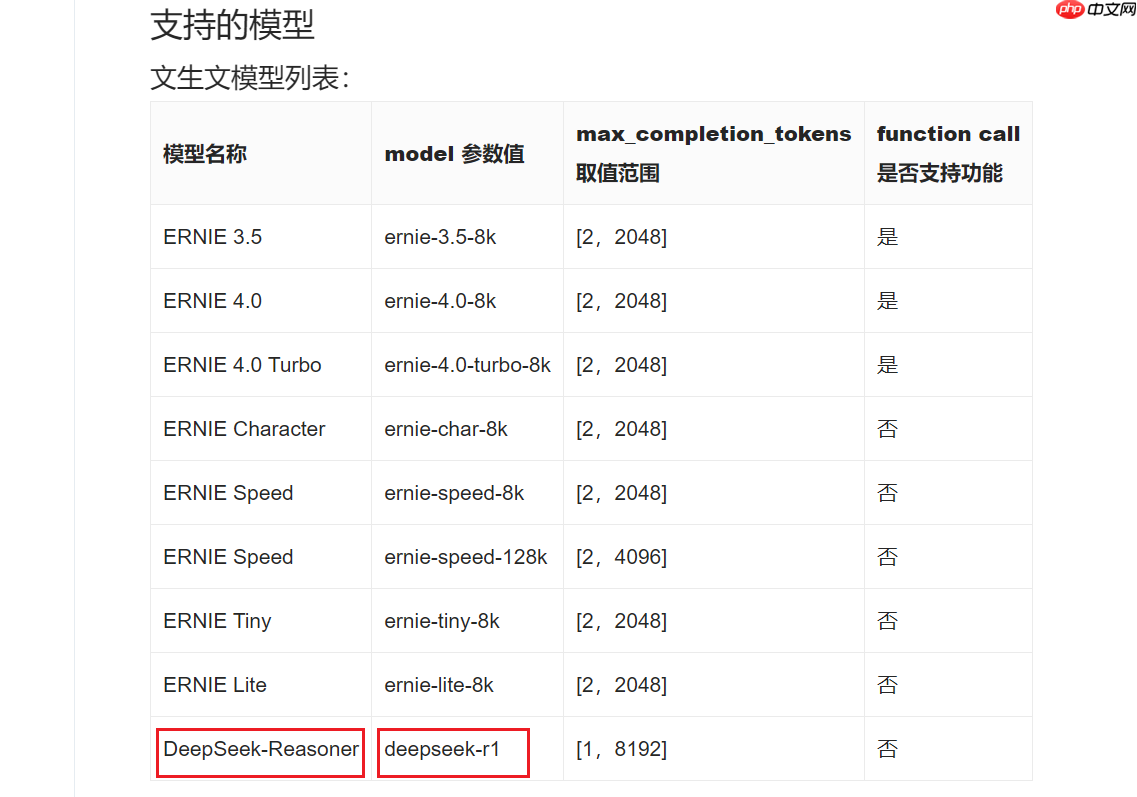
填完参数后,一键即可调用!
文生文
含有 AI Studio 访问令牌的环境变量,https://aistudio.baidu.com/account/accessToken,
如果想跑通DEMO,那么就要在下面的代码中更换你的AI_STUDIO_API_KEY。 In []
import os os.environ["AI_STUDIO_API_KEY"] = "your_access_token"登录后复制 In []
```python import osclient = OpenAI( api_key=os.getenv('AI_STUDIO_API_KEY'), # 含有AI Studio访问令牌的环境变量,https://aistudio.baidu.com/account/accessToken, base_url='https://aistudio.baidu.com/llm/lmapi/v, )chat_completion = client.chat.completions.create( messages=[ {'role': 'system', 'content': '你是开发者助理,精通开发知识,提供搜索帮助建议。'}, {'role': 'user', 'content': '你好,请介绍一下你自己'} ], model='deepseek-r, temperature= )print(chat_completion.choices[.message.content) ```
多轮对话
In []
import os from openai import OpenAI def get_response(messages): client = OpenAI( api_key=os.environ.get("AI_STUDIO_API_KEY"), # 含有 AI Studio 访问令牌的环境变量,https://aistudio.baidu.com/account/accessToken, base_url="https://aistudio.baidu.com/llm/lmapi/v3", # aistudio 大模型 api 服务域名 ) completion = client.chat.completions.create(model="ernie-3.5-8k", messages=messages) return completion messages = [ { "role": "system", "content": "你是 AI Studio 开发者助理,你精通开发相关的知识,负责给开发者提供搜索帮助建议。", } ] assistant_output = "您好,我是AI Studio 开发者助理,请问有什么能帮助你的吗?" print(f"""输入:"结束",结束对话 """) print(f"模型输出:{assistant_output} ") user_input = "" while "结束" not in user_input: user_input = input("请输入:") # 将用户问题信息添加到messages列表中 messages.append({"role": "user", "content": user_input}) assistant_output = get_response(messages).choices[0].message.content # 将大模型的回复信息添加到messages列表中 messages.append({"role": "assistant", "content": assistant_output}) print(f"模型输出:{assistant_output}") print(" ")登录后复制
流式输出
In []
import osfrom openai import OpenAIclient = OpenAI( api_key=os.environ.get(AI_STUDIO_API_KEY), # 含有 AI Studio 访问令牌的环境变量,https://aistudio.baidu.com/account/accessToken, base_url=https://aistudio.baidu.com/llm/lmapi/v)completion = client.chat.completions.create( model=ernie-, messages=[ {role: system, content: 你是 AI Studio 实训AI开发平台的开发者助理,精通开发相关知识,提供搜索帮助。}, {role: user, content: 你好,请介绍一下AI Studio} ], stream=True)for chunk in completion: print(chunk.choices[.delta.content or , end=)
异步调用
来自开发者的提醒:在异步调用前使用nest_asyncio.apply(),
原因:Python的asyncio框架不允许在已启动的事件循环内再创建新的事件循环,这会导致异常运行时错误:This event loop is already running。
nest_asyncio通过打补丁的方式,允许在已有的事件循环中运行新的事件循环,从而解决了这一限制。 In []
!pip install nest_asyncio登录后复制 In []
import nest_asyncio nest_asyncio.apply()登录后复制 In []
import osfrom openai import AsyncOpenAIimport asyncioclient = AsyncOpenAI( api_key=os.environ.get(AI_STUDIO_API_KEY), # 含有 AI Studio 访问令牌的环境变量,https://aistudio.baidu.com/account/accessToken, base_url=https://aistudio.baidu.com/llm/lmapi/v # aistudio 大模型 api 服务域名 )async def main: chat_completion = await client.chat.completions.create( messages=[ {role: system, content: 你是 AI Studio 实训AI开发平台的开发者助理,你精通开发相关的知识,负责给开发者提供搜索帮助建议.}, {role: user, content: 你好,请介绍一下AI Studio} ], model=ernie- ) print(chat_completion.choices[.message.content)asyncio.run(main)
打印思维链(DeepSeek-R1)
是的,这是DeepSeek-R1的专属功能!
非流式
In []
import osfrom openai import OpenAIclient = OpenAI( api_key=os.environ.get(AI_STUDIO_API_KEY), # 含有 AI Studio 访问令牌的环境变量,https://aistudio.baidu.com/account/accessToken, base_url=https://aistudio.baidu.com/llm/lmapi/v)chat_completion = client.chat.completions.create( messages=[ {role: system, content: 你是 AI Studio 实训AI开发平台的开发者助理,你精通开发相关的知识,负责给开发者提供搜索帮助建议。}, {role: user, content: 你好,请介绍一下AI Studio} ], model=deepseek-r)print(chat_completion.choices[.message.reasoning_content)print(chat_completion.choices[.message.content)
流式
In []
import osclient = OpenAI( api_key=os.environ.get('AI_STUDIO_API_KEY'), # 含有 AI Studio 访问令牌的环境变量,获取方式见https://aistudio.baidu.com/account/accessToken, base_url='https://aistudio.baidu.com/llm/lmapi/v)completion = client.chat.completions.create( model='deepseek-r, messages=[ {'role': 'system', 'content': '你是 AI Studio 实训AI开发平台的开发者助理,你精通开发相关的知识,负责给开发者提供搜索帮助建议'}, {'role': 'user', 'content': '你好,请介绍一下AI Studio'} ], stream=True, )for chunk in completion: if hasattr(chunk.choices[.delta, 'reasoning_content') and chunk.choices[.delta.reasoning_content: print(chunk.choices[.delta.reasoning_content, end='', flush=True) else: print(chunk.choices[.delta.content, end='', flush=True)
三、星河社区一键部署(推荐)

部署链接:https://aistudio.baidu.com/deploy/mine
AIStudio平台现在可以全自动化部署DeepSeek-R1了!
- 首先点击进入部署页面。
也可以在侧边栏找到一键部署
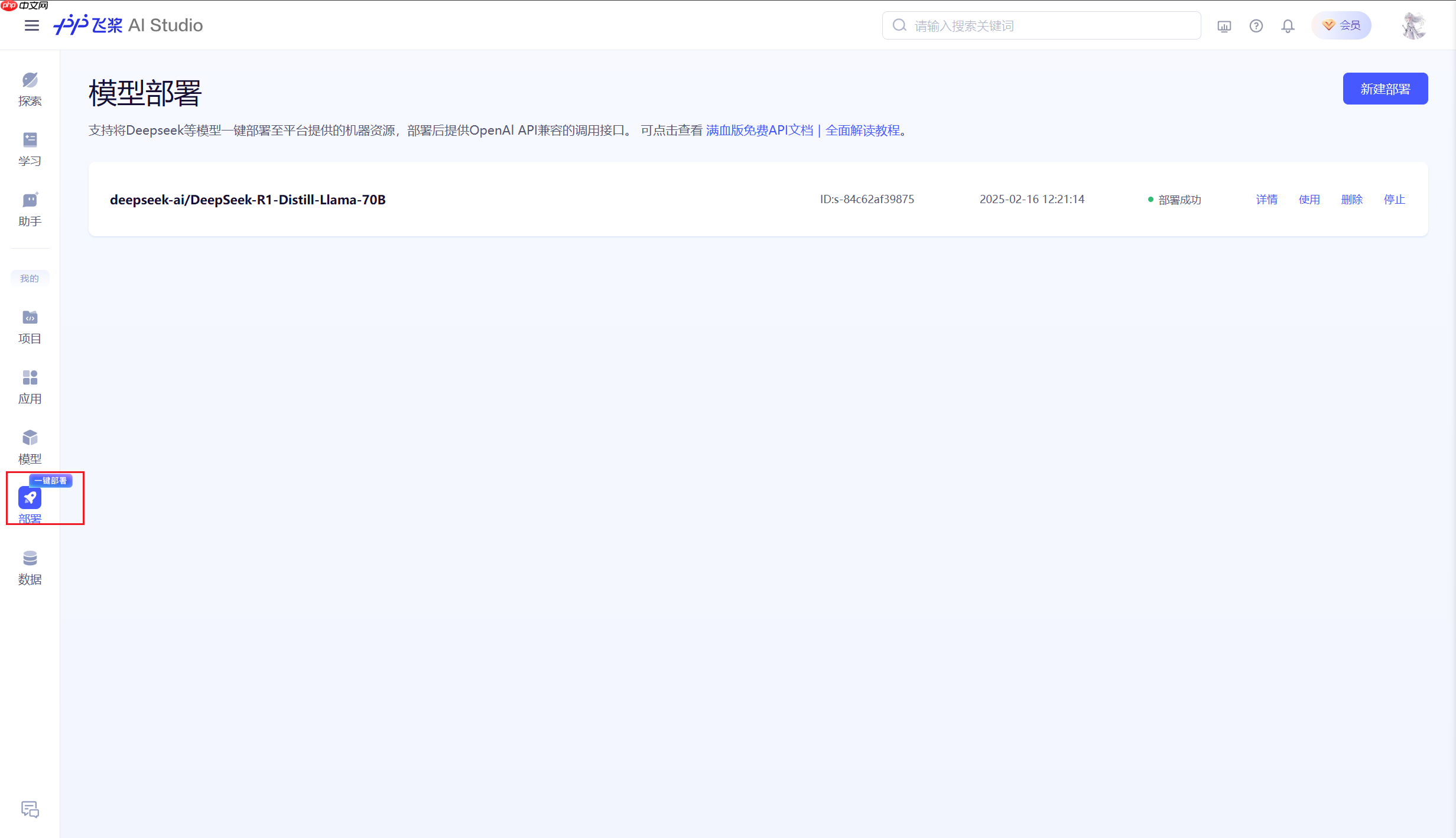

- 进入部署界面后,点击新建部署。
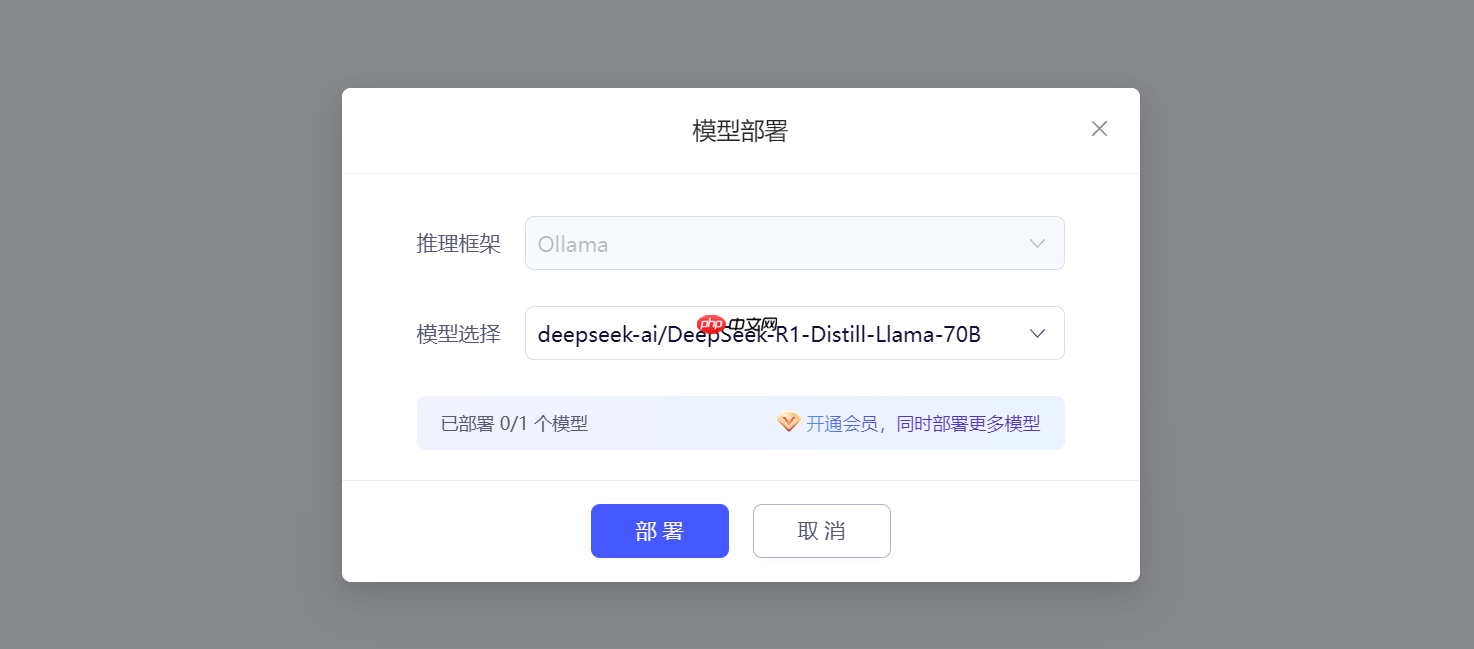
模型部署窗口。推理框架:首选Ollama,不可更改。 模型挑选:依据需求自选,采用deepseek-ai/DeepSeek-RDistill-Llama-。
选择完成后,点击部署。
- 等待部署成功
当出现下图红框内容时,代表模型部署成功。

- 获取APIKey和BaseURL
单击使用,弹出下图的使用代码。
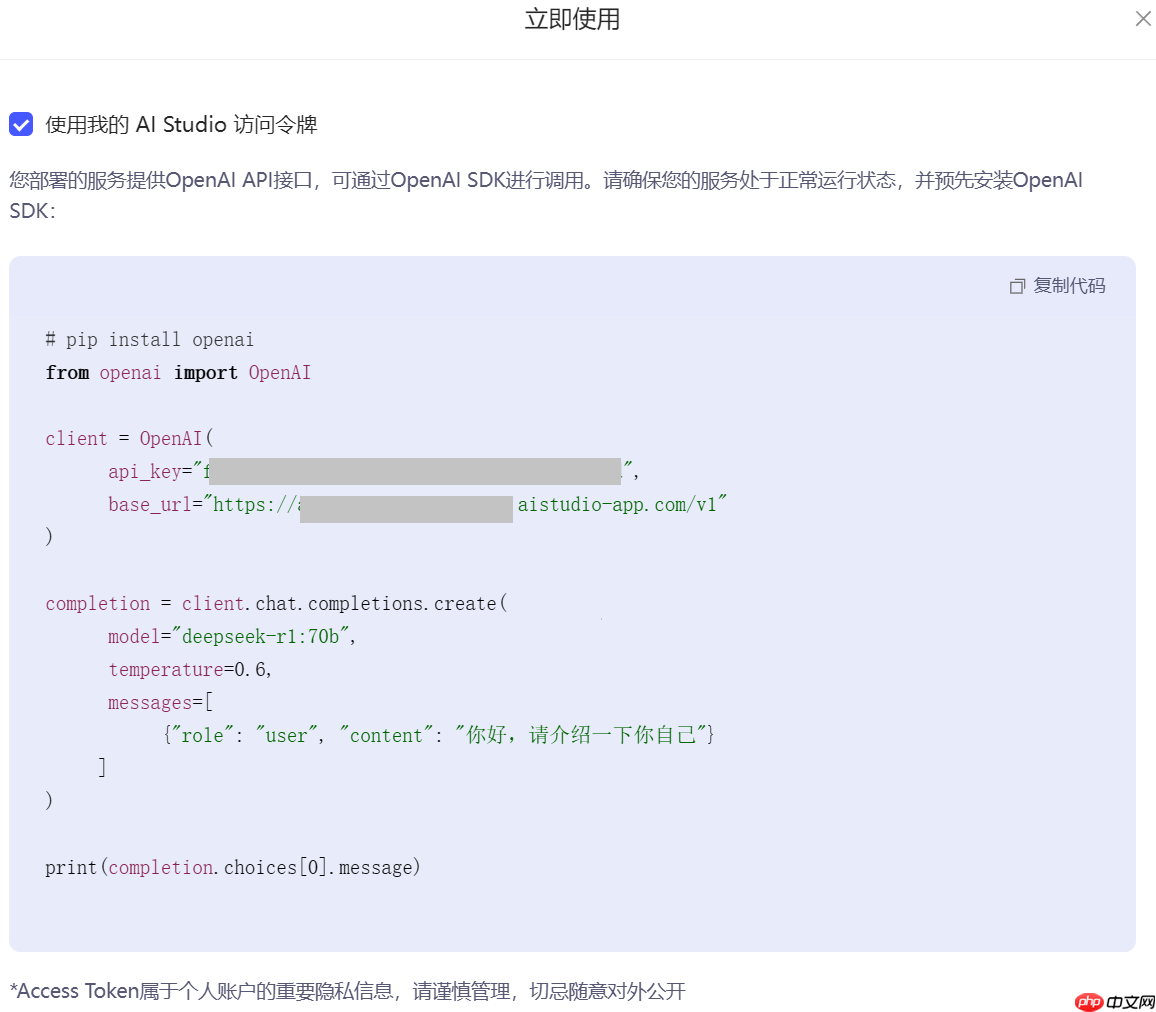
下面做一个测试。
事实上,**二、星河大模型 API 服务(推荐)**中的代码是通用的。 In [4]
- 从我们的对话中,您是一个非常友好的助手。请问有什么问题我可以帮助您的?
<think> 您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。 </think> 您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。登录后复制
四、Ollama本地部署
这种方式可能是AIStudio中最流行的了。
感谢阿斯顿aaC提供ollama安装包和deepseek-r1模型,放置于公共数据集deepseek-r1中。
整合包提供的是deepseek-r1的7B的Q4_K_M的量化版本,大家可以根据需要自行更换参数量。
deepseek-r1在ollama上的位置:https://ollama.com/library/deepseek-r1
1.环境配置
用于在本地环境中安装并启动 Ollama 服务,通过创建文件夹、解压安装包以及运行服务命令,
以便后续使用 Ollama 进行模型加载和推理等操作,运行成功可看到下图。 In []
# 1. 在根目录下创建`ollama`文件夹!mkdir ollama# 2. 解压ollama!tar -C ollama -xzf data/data315295/ollama-linux-amd64.tgz# 3. 解压deepseek-r1模型!tar -zxvf data/data315295/ollama-models.tar.gz# 4. 复制模型文件到.ollama路径(这是Ollama存放模型的目录, 这样就可以省去从网络下载模型的步骤)!cp -r ./models .ollama# 5. 删除解压的模型文件, 其实3和4可以合并为一步 mv 命令,懒得改了!rm -rf models/登录后复制
在 Linux 系统中,Ollama 默认将模型存储在/usr/share/ollama/.ollama/models目录,
如果一切正常,那么执行tree /home/aistudio/.ollama,应该会得到如下的结构
- 我找到了你的模型信息,包括多个版本的SHA希值和最新的manifests。现在可以进行后续操作了。
这样,在部署模型时,Ollama就能找到本地的模型权重了。
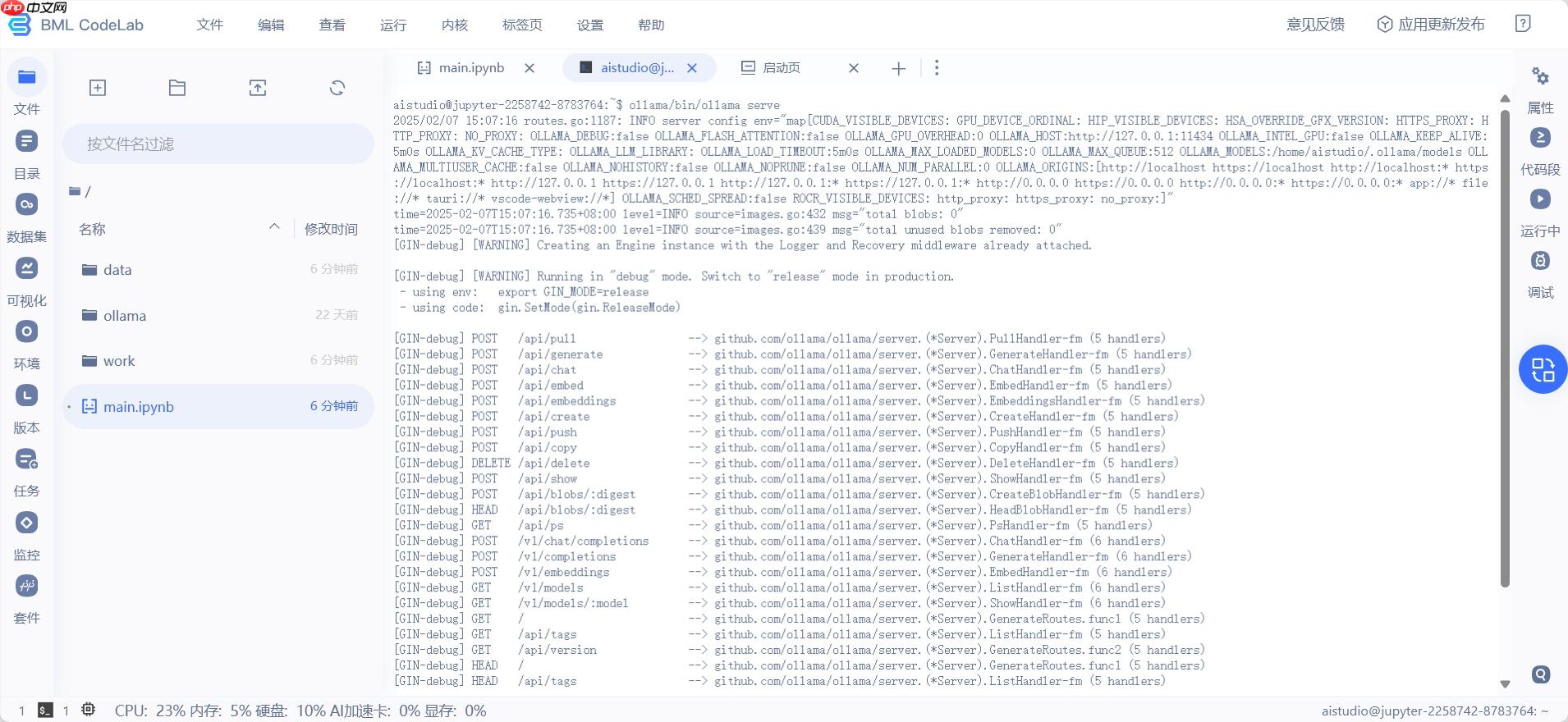
2.启动Ollama服务
在终端中执行如下命令:
ollama/bin/ollama serve登录后复制
运行成功可看到下图。
通过如下命令可以查看本地已有的模型权重,不需要特意前往终端执行。 In [4]
# 查看模型!ollama/bin/ollama ls登录后复制
NAME ID SIZE MODIFIED deepseek-r1:latest 0a8c26691023 4.7 GB About a minute ago登录后复制
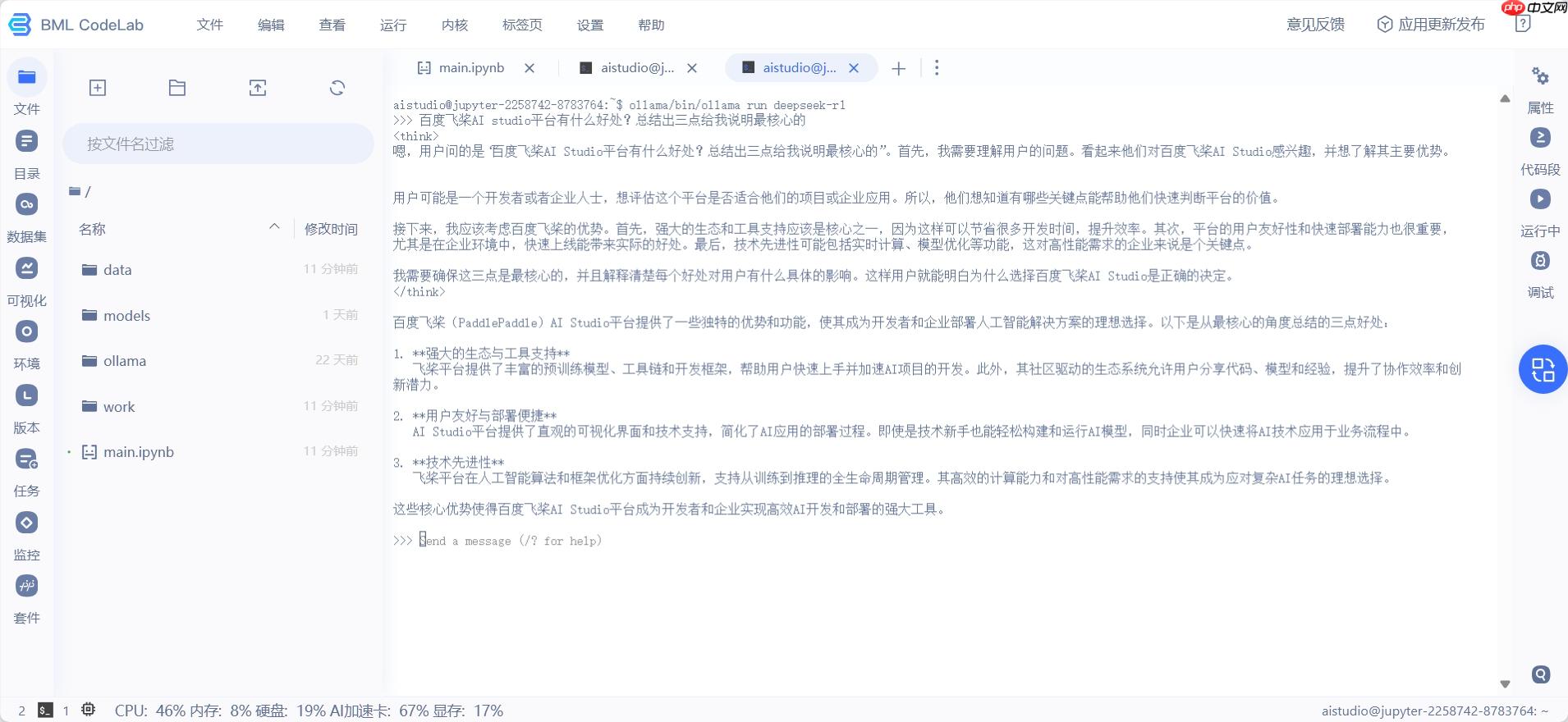
3.部署deepseek-r1模型
通过如下命令可以启动模型。
在终端中执行。
ollama/bin/ollama run deepseek-r1登录后复制
执行成功如下图。
4.快速推理
老样子,配置OpenAI客户端。
二、星河大模型 API 服务(推荐)中的代码仍然可以使用(配置完客户端后)。 In []
使用OpenAI SDK,配置连接到本地API服务器并调用聊天模型进行对话。以下是解释人工智能、机器学习和深度学习三者关系的示例输出:人工智能、机器学习和深度学习是三个相互联系的概念。人工智能关注的是让计算机执行人类智能的任务;机器学习是从数据中学习模式以实现更准确预测;而深度学习是一种特殊的机器学习方法,使用多层神经网络从大量数据中提取特征。
五、PaddleNLP 3.0部署
严格地将,基于PaddleNLP 3.0部署DeepSeek-R1进行本地访问,这种方式被划分为“调用”类别更合适。
使用PaddleNLP在飞桨星河社区一键迅速部署DeepseekR1,在本地通过API远程访问。
参考项目:【PaddleNLP 3.0】轻松动手玩转DeepSeek-R1
1.环境配置
采用V100和A100环境。执行以下操作即可。 In [1]
自动确认并卸载已安装的 PaddleNLP 库! 自动确认并卸载已安装的 PaddleNLP 库! ```bash pip uninstall paddlenlp -y ``` 解压安装 PaddleNLP,文件来自 GitHub 仓库 develop 分支()! ```bash tar -xf PaddleNLP-tgz ``` 创建一个名为 'external-libraries' 的目录,用于存放安装的外部库。(星河平台默认安装库重启后会被清空,所以需要将安装的库放到外部目录中) ```bash mkdir -p /home/aistudio/external-libraries ``` 创建环境依赖库,针对不同的 GPU 环境,请使用者自行切换! ```bash !mkdir -p /home/aistudio/external-libraries tar zxf external-libraries.tgz ``` 依赖文件已经安装在 'external-libraries' 中,无需再次安装。登录后复制以下内容至相应位置即可。确保按步骤操作,以避免环境冲突和依赖问题。
Found existing installation: paddlenlp 2.8.1 Uninstalling paddlenlp-2.8.1: Successfully uninstalled paddlenlp-2.8.1登录后复制
2.快速推理
In [2]
将自定义的外部库目录添加到系统的路径中,以使Python能够导入这些库中的模块: ```python import sys # 添加包含已安装外部库的目录到系统路径 sys.path.insert( '/home/aistudio/external-libraries') ``` 同时,将PaddleNLP项目的根目录添加到系统的路径中,以便可以导入其模块和包: ```python sys.path.insert( '/home/aistudio/PaddleNLP') ``` 登录并复制后的代码如下:```python # 将自定义的外部库目录添加到系统的路径中,以使Python能够导入这些库中的模块: import sys# 添加包含已安装外部库的目录到系统路径 sys.path.insert( '/home/aistudio/external-libraries')# 同时,将PaddleNLP项目的根目录添加到系统的路径中,以便可以导入其模块和包: sys.path.insert( '/home/aistudio/PaddleNLP') ```
PaddleNLP 3.0 支持模型名称如下: deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B deepseek-ai/DeepSeek-R1-Distill-Qwen-7B deepseek-ai/DeepSeek-R1-Distill-Qwen-14B (A100 40G环境可以使用) deepseek-ai/DeepSeek-R1-Distill-Qwen-32B (A100 40G环境可以使用, wint8量化) deepseek-ai/DeepSeek-R1-Distill-Llama-8B deepseek-ai/DeepSeek-R1-Distill-Llama-70B (需4卡V100 32G环境) In [3]
导入Paddle,使用llm.predict模块创建预测器。安装了paddlenlp_ops算子后需重启内核启用,并支持多种模型名称如Qwen-、Qwen-等。
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/utils/cpp_extension/extension_utils.py:686: UserWarning: No ccache found. Please be aware that recompiling all source files may be required. You can download and install ccache from: https://github.com/ccache/ccache/blob/master/doc/INSTALL.md warnings.warn(warning_message) /home/aistudio/external-libraries/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm /opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/_distutils_hack/__init__.py:31: UserWarning: Setuptools is replacing distutils. Support for replacing an already imported distutils is deprecated. In the future, this condition will fail. Register concerns at https://github.com/pypa/setuptools/issues/new"https://img.php.cn/upload/article/001/571/248/175263455756226.jpg" >
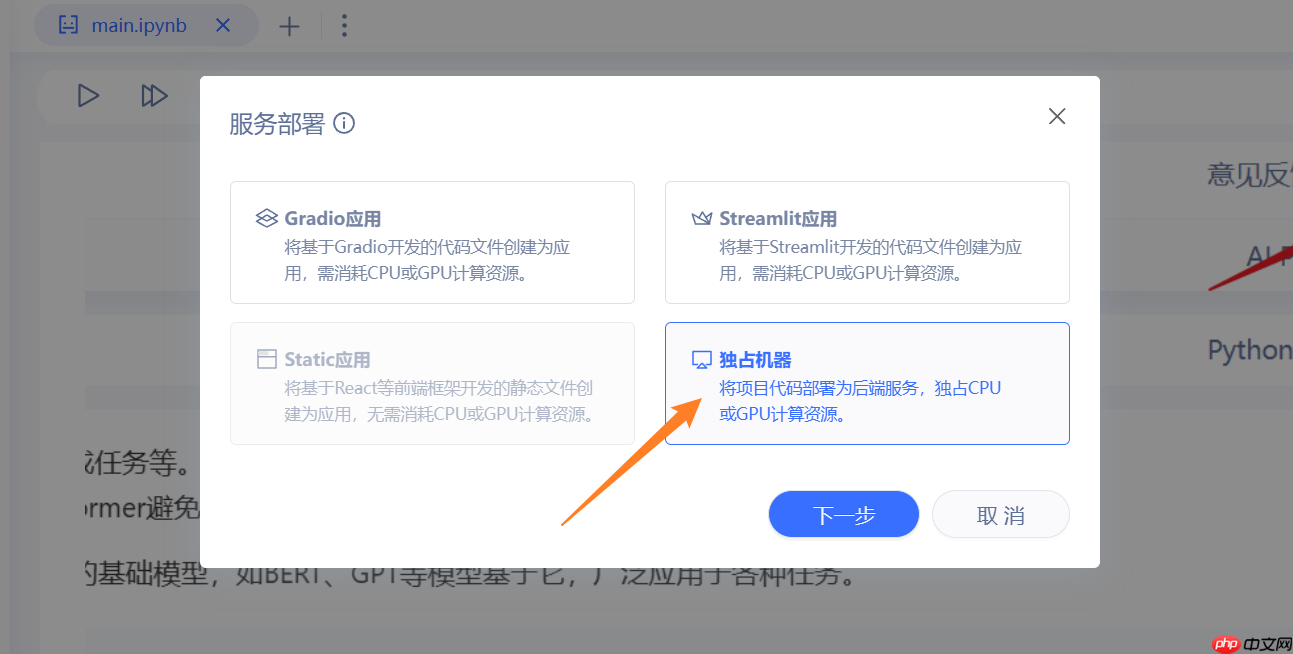
- 选择独占机器,选择下一步
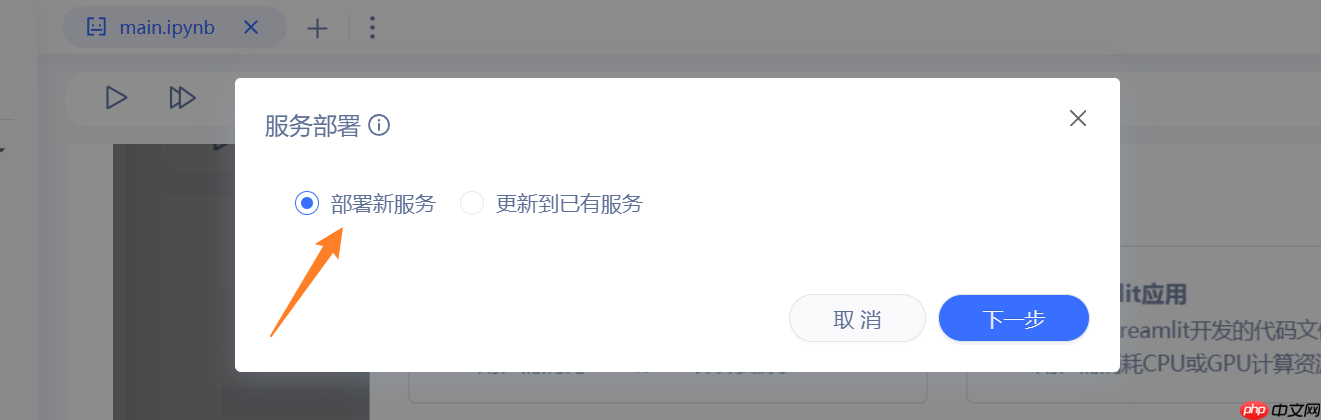
- 选择部署新服务,选择下一步
当你启动服务时,请使用以下命令: 服务启动:`python server.py` 应用部署包位置:无需更改,保持原样。 监听端口:无需修改,与上一个参数保持一致。 运行环境:选择GPU至尊版。 访问权限:所有用户均可访问;私有资源需鉴权,公开资源可被大众使用。
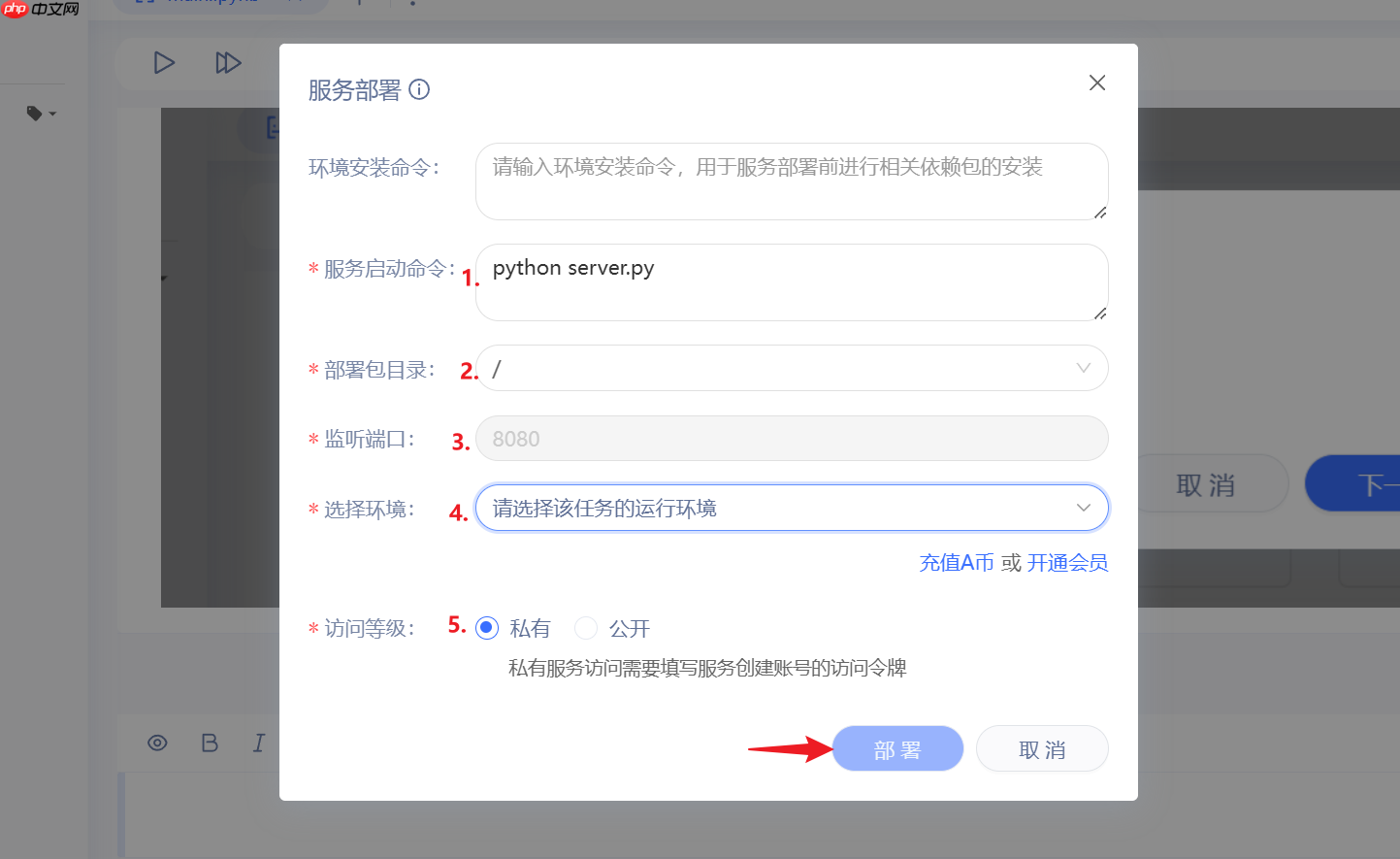
- 最后点击部署,等待一段时间(可能10分钟还要久),即可
调用模型
需要从项目界面的服务部署子页面,获取AI Studio的API_URL,记录下。
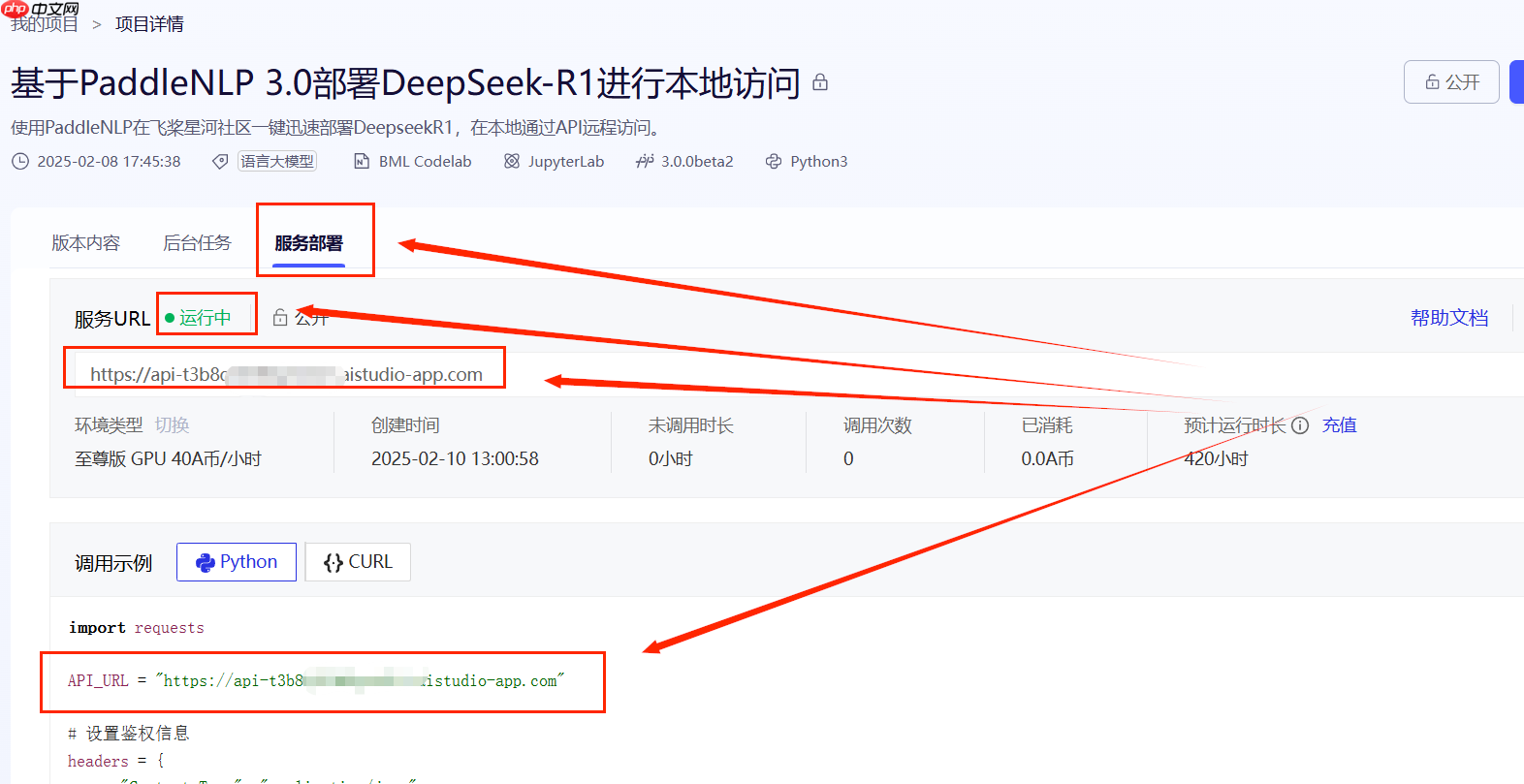
将下面代码中的API_URL替换为你的API_URL,调整input_text即可执行。
与其他方法相比,这种方法没有依赖于OpenAI库或进行多轮对话的能力,而是提供了一种单一方向的回应方式。
import requests API_URL = "https://***************.aistudio-app.com" # AI Studio接口地址input_text = "诗三百收录了多少篇李白的诗歌?" # 输入文本# 请求头headers = { "Content-Type": "application/json"}# 发送请求response = requests.post(API_URL, json={'input_text': input_text}, headers=headers, timeout=3600, verify=False)print(response.content.decode('utf-8'))登录后复制
自定义服务端
服务端使用的模型是deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B,如果希望替换为其他模型,可以修改server.py第14行。
PaddleNLP 3.0 支持模型名称如下: deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B deepseek-ai/DeepSeek-R1-Distill-Qwen-7B deepseek-ai/DeepSeek-R1-Distill-Qwen-14B (A100 40G环境可以使用) deepseek-ai/DeepSeek-R1-Distill-Qwen-32B (A100 40G环境可以使用, wint8量化) deepseek-ai/DeepSeek-R1-Distill-Llama-8B deepseek-ai/DeepSeek-R1-Distill-Llama-70B (需4卡V100 32G环境)
如果你想丰富服务端的功能,可以修改 32行 到 41行。 In []
@app.route('/', methods=['POST'])def home(): # 从POST请求中获取input_text input_text = request.json.get('input_text', "") print(f"input_text: {input_text}") result = predictor.predict(input_text)[0] # output = result.replace("<think>\n", "```\n").replace("</think>\n", "```\n") print(f"result: {result}") return result登录后复制
以上就是【Tutorial】一文学会在AIStudio上部署Deepseek-R1的详细内容,更多请关注其它相关文章!
热门推荐
-
【Tutorial】一文学会在AIStudio上部署Deepseek-R1该项目总结了AIStudio上主流的DeepSeek-R用方式,省去了开发者需要进行调研的工作,从而加速平台项目的繁荣发展
-
 【AI达人创造营第二期】 一文读懂双向循环神经网络 BRNN本研究全面解析了RNN与BRNN的基础知识、架构及各自的利弊,并通过一个案例展示了基于vanillaRNN、LSTM、BiLSTM、GRU以及BiGRU模型的谣言
【AI达人创造营第二期】 一文读懂双向循环神经网络 BRNN本研究全面解析了RNN与BRNN的基础知识、架构及各自的利弊,并通过一个案例展示了基于vanillaRNN、LSTM、BiLSTM、GRU以及BiGRU模型的谣言 -
 破碎之地会在2025年6月上线吗 破碎之地正式上线时间分享破碎之地将在上线吗?尚未有确切消息公布。该游戏将呈现独特的末世废土美学,为玩家打造一个未知的沉浸式冒险空间
破碎之地会在2025年6月上线吗 破碎之地正式上线时间分享破碎之地将在上线吗?尚未有确切消息公布。该游戏将呈现独特的末世废土美学,为玩家打造一个未知的沉浸式冒险空间 -
 继花村阳介后 里中千枝的英配也不会在《女神异闻录4重制版》回归 或与工会罢工有关昨晚,女神异闻录村阳介的英配演员YuriLowenthal发表声明称他不会在传闻中的女神异闻录制版中回归
继花村阳介后 里中千枝的英配也不会在《女神异闻录4重制版》回归 或与工会罢工有关昨晚,女神异闻录村阳介的英配演员YuriLowenthal发表声明称他不会在传闻中的女神异闻录制版中回归 -
 得物快递信息会在菜鸟上显示吗_得物会在菜鸟上显示吗大家知道在购物,或者有朋友给你寄快递的时候,你的快递信息会自动出现在菜鸟驿站信息中,很多用户想知道得物快递信息会不会在菜鸟驿站快递信息中呢?一起来看看吧
得物快递信息会在菜鸟上显示吗_得物会在菜鸟上显示吗大家知道在购物,或者有朋友给你寄快递的时候,你的快递信息会自动出现在菜鸟驿站信息中,很多用户想知道得物快递信息会不会在菜鸟驿站快递信息中呢?一起来看看吧 -
 无需密钥 / 控制台:GitHub 用户现可免费使用 / 部署 GPT-4o、DeepSeek-R1 等 AI 模型 A新闻速递!GitHub今日宣布开源模型API,对所有用户免费开放,支持OpenAI规范,带来极大便利
无需密钥 / 控制台:GitHub 用户现可免费使用 / 部署 GPT-4o、DeepSeek-R1 等 AI 模型 A新闻速递!GitHub今日宣布开源模型API,对所有用户免费开放,支持OpenAI规范,带来极大便利 -
 如何让本地部署的 DeepSeek 更“懂”你?在使用过DeepSeek的朋友中,大家可能会遇到一个常见的问题:官网的API总是会中断连接,而且当我们尝试将DeepSeek部署到本地运行时,它也会表现出相当低效
如何让本地部署的 DeepSeek 更“懂”你?在使用过DeepSeek的朋友中,大家可能会遇到一个常见的问题:官网的API总是会中断连接,而且当我们尝试将DeepSeek部署到本地运行时,它也会表现出相当低效 -
 DeepSeek-VL2部署教程一、介绍今天,我们自豪地宣布了DeepSeek-VL这一创新系列一组先进的大型混合专家(M
DeepSeek-VL2部署教程一、介绍今天,我们自豪地宣布了DeepSeek-VL这一创新系列一组先进的大型混合专家(M