豆包AI安装后如何配置多GPU并行 豆包AI分布式计算环境搭建
时间:2025-07-16 10:43:42
本篇文章详细阐述了豆包AI在配置后能如何利用多GPU进行高效的并行计算,提高系统的性能和效率。我们将指导您完成从安装到成功搭建过程中的关键步骤,确保您能够最大程度地释放您的多GPU设备的能力。通过遵循我们的教程,您可以快速实现分布式计算的优化和提升。

准备工作
在开始进行配置前,请确认您的系统已经配备了必需的硬件设备,例如多块GPU并确保它们能由操作系统的版本识别。此外,需下载及安装与之相匹配的GPU驱动程序,这一步是确保豆包AI能够高效运行的关键所在。
安装豆包AI
为实现流畅的学习与交互体验,请详读官方文档,准确执行安装流程。确认所选环境满足系统要求后,确保所有必要依赖项已正确配置,并将豆包AI的安装目录设在易于管理和维护的位置。如尚未设置,现着手完成此步骤,以保障顺利启动和使用。

配置环境库
在分布式计算领域,豆包AI依赖特定的环境库,例如用于通信的NCCL或MPI。为了确保豆包AI在您系统中的成功运行,请参考官方文档进行详细安装。完成后,配置必要的环境变量以使豆包AI能够识别并使用这些库,实现高效协作与数据处理。
设置节点信息
在多GPU并行环境中,您需要配置各个计算节点的信息。这包括每个节点的IP地址、端口号以及该节点上可用的GPU数量。通常,豆包AI会提供一个配置文件或命令行参数来完成这项设置。确保所有节点的信息都准确无误,以便它们能够相互发现并进行通信。
立即进入“豆包AI人工智官网入口”;
立即学习“豆包AI人工智能在线问答入口”;
配置分布式训练策略
豆包AI的分布式训练策略极大地影响了数据如何被划分、模型在不同节点之间同步以及梯度的聚合方式。常见的策略包括数据并行和模型并行,您需要根据自己的具体模型和数据集选择最适合的方法,并在配置文件或训练脚本中进行相应的设置。例如,在数据并行中,将相同的数据复制到每个GPU上并分布在各个节点计算,最后通过梯度的聚合来更新整个模型。而在模型并行中,则是将整个模型分割到不同的GPU上进行处理。这些分布式训练策略大大提高了训练效率和性能,使得训练大型复杂模型成为可能,同时也需要根据实际需求灵活选择最适合自己的方法。

启动分布式训练
完成以上配置后,您就可以开始使用豆包AI的分布式训练了。通常情况下,启动方式是通过一个脚本来实现的,该脚本会在各个节点上启动豆包AI的工作进程。在运行过程中,您可以指定主节点和工作节点的数量,同时可以查看日志输出以确定分布式训练是否成功完成。
监控与调试
在训练过程中,持续监控设备资源(如GPU的使用率、内存占用和通信情况)至关重要。这能帮助识别潜在的性能瓶颈或配置错误。当遇到问题时,查看日志文件或利用系统内置工具定位问题是常见做法。调试步骤可能涉及检查网络连接、确认驱动兼容性以及调整环境变量设置。
性能优化建议
在追求高效分布式训练的过程中,采取明智的数据处理策略、选用最佳通信工具以及优化模型并行架构至关重要。通过调整数据加载并行度、选择恰当的通信库和设计高效的模型并行策略,可以显著提升系统性能。此外,探索多种参数组合和配置方案也是关键一步,旨在为特定场景定制最佳解决方案。
以上就是豆包AI安装后如何配置多GPU并行 豆包AI分布式计算环境搭建的详细内容,更多请关注其它相关文章!
热门推荐
-
豆包AI安装后如何配置多GPU并行 豆包AI分布式计算环境搭建本篇文章详细阐述了豆包AI在配置后能如何利用多GPU进行高效的并行计算,提高系统的性能和效率。我们将指导您完成从安装到成功搭建过程中的关键步骤,确保您能够最大程度
-
 抖音豆包概念股是什么随着互联网科技的飞速发展,短视频平台成为了人们生活中不可或缺的一部分。在众多短视频应用中,抖音凭借其强大的内容生态和庞大的用户基础,吸引了无数用户的关注
抖音豆包概念股是什么随着互联网科技的飞速发展,短视频平台成为了人们生活中不可或缺的一部分。在众多短视频应用中,抖音凭借其强大的内容生态和庞大的用户基础,吸引了无数用户的关注 -
 豆包app收费吗豆包APP是一款由字节跳动推出的Chat类产品,它是一款非常实用且方便的软件,可以让用户与AI机器人进行交流。这款系统类软件可以回答各种类型的问题,包括常识问题、科学问题、技术问题等。用户无需申请或等待,只需注册即可免费使用。
豆包app收费吗豆包APP是一款由字节跳动推出的Chat类产品,它是一款非常实用且方便的软件,可以让用户与AI机器人进行交流。这款系统类软件可以回答各种类型的问题,包括常识问题、科学问题、技术问题等。用户无需申请或等待,只需注册即可免费使用。 -
 关闭抖音对豆包授权方法豆包是一个通用的人工智能,能够回复各种类型的问题,囊括学问问题、科学问题、手艺问题等。豆包APP能够抖音一键登录,但是一些朋友不想在两个一块用了,那么抖音授权豆包如何关掉呢?接下来是小编给网友带来了关掉抖音对豆包授权教程,好奇的玩家们一块来瞧瞧吧。
关闭抖音对豆包授权方法豆包是一个通用的人工智能,能够回复各种类型的问题,囊括学问问题、科学问题、手艺问题等。豆包APP能够抖音一键登录,但是一些朋友不想在两个一块用了,那么抖音授权豆包如何关掉呢?接下来是小编给网友带来了关掉抖音对豆包授权教程,好奇的玩家们一块来瞧瞧吧。 -
 抖音豆包app介绍豆包是字节跳动公司基于云雀模子开发的AI工具,供应聊天机器人、写作助手以及英语学习助手等功能。豆包app是一款很适用很利便能够让你们和AI机器人聊天的系统类软件,网友使用语音输入即可与之聊天,还能够为你的豆包设置不同音质,切换豆包的声响。值得一提的是,网友能够经过豆包客户端训练和定制属于自个的智能体,特别加倍吻合你的聊天喜欢,专属你的私人聊天助力!
抖音豆包app介绍豆包是字节跳动公司基于云雀模子开发的AI工具,供应聊天机器人、写作助手以及英语学习助手等功能。豆包app是一款很适用很利便能够让你们和AI机器人聊天的系统类软件,网友使用语音输入即可与之聊天,还能够为你的豆包设置不同音质,切换豆包的声响。值得一提的是,网友能够经过豆包客户端训练和定制属于自个的智能体,特别加倍吻合你的聊天喜欢,专属你的私人聊天助力! -
 海信电视怎么安装当贝市场 海信电视怎么安装当贝市场,教你方法1、载当贝市场的安装包,搜索当贝市场,进入官网点击“立即下载”下载安装包,并复制到U盘。2、按遥控器上的设置键或在我的应用里找到设置,在设置里找到通用--商场模式,选择开启商场模式。3、将下载了当贝市场安装包的U盘插到海
海信电视怎么安装当贝市场 海信电视怎么安装当贝市场,教你方法1、载当贝市场的安装包,搜索当贝市场,进入官网点击“立即下载”下载安装包,并复制到U盘。2、按遥控器上的设置键或在我的应用里找到设置,在设置里找到通用--商场模式,选择开启商场模式。3、将下载了当贝市场安装包的U盘插到海 -
 touch it rikka游戏下载安装touch it rikka是近来很多玩家都在玩的一款游戏,当前手机版也已经上线了,让网友能够在手机里直接下载安装,无限畅玩哦!这边小编就为网友带来了touch it rikka游戏下载安装,touch it rikka正版中文版下载,好奇的小伙伴们不要错过了。
touch it rikka游戏下载安装touch it rikka是近来很多玩家都在玩的一款游戏,当前手机版也已经上线了,让网友能够在手机里直接下载安装,无限畅玩哦!这边小编就为网友带来了touch it rikka游戏下载安装,touch it rikka正版中文版下载,好奇的小伙伴们不要错过了。 -
 十大禁用app软件免费下载大全2023已更新 十大禁用app软件免费安卓下载安装十大禁用app软件免费下载大全2023已更新:对于这类的软件还是相当多的,各种软件功能还是相当全面的,当然这类软件都是免费非常有特色。小编整理了一些比较不错的软件,比如视频、漫画、直播、聊天交友等,下面一起来看看相关的信息。
十大禁用app软件免费下载大全2023已更新 十大禁用app软件免费安卓下载安装十大禁用app软件免费下载大全2023已更新:对于这类的软件还是相当多的,各种软件功能还是相当全面的,当然这类软件都是免费非常有特色。小编整理了一些比较不错的软件,比如视频、漫画、直播、聊天交友等,下面一起来看看相关的信息。 -
 奔图打印机安装步骤_奔图打印机怎么连接电脑-奔图打印机安装使用教程奔图打印机安装步骤是什么,奔图打印机应该怎么去连接电脑呢,都是大家比较关心的问题,具体的安装步骤是什么呢,小编整理了相关的安装方法,希望能够对大家有所帮助。
奔图打印机安装步骤_奔图打印机怎么连接电脑-奔图打印机安装使用教程奔图打印机安装步骤是什么,奔图打印机应该怎么去连接电脑呢,都是大家比较关心的问题,具体的安装步骤是什么呢,小编整理了相关的安装方法,希望能够对大家有所帮助。 -
 小米应用商店怎么禁止下载软件安装_小米应用商店禁止下载设置方法介绍小米应用商店禁止下载设置方法介绍:对于小米应用商店这款软件使用起来还是挺不错的,当然在这款软件中禁止下载安装软件又该如何搞呢?这也是很多玩家不了解的,小编整理了相关诶荣介绍,下面一起来看看相关的信息。
小米应用商店怎么禁止下载软件安装_小米应用商店禁止下载设置方法介绍小米应用商店禁止下载设置方法介绍:对于小米应用商店这款软件使用起来还是挺不错的,当然在这款软件中禁止下载安装软件又该如何搞呢?这也是很多玩家不了解的,小编整理了相关诶荣介绍,下面一起来看看相关的信息。 -
 华为手机上传到中转站怎么关闭 华为手机如何关闭上传到中转站华为手机如何关闭上传到中转站:对于华为手机不少用户都在使用啦,当然这可手机功能也是非常强大的。对于这款世界如何关闭上传到中转站呢?小编为玩家整理了相关内容,下面一起来看看相关的信息。
华为手机上传到中转站怎么关闭 华为手机如何关闭上传到中转站华为手机如何关闭上传到中转站:对于华为手机不少用户都在使用啦,当然这可手机功能也是非常强大的。对于这款世界如何关闭上传到中转站呢?小编为玩家整理了相关内容,下面一起来看看相关的信息。 -
 三国志11威力加强版庙和遗迹如何触发 三国志11庙和遗迹坐标位置机制详解三国志11威力加强版庙和遗迹如何触发:在三国志11游戏中很多玩法还是挺多的,对于游戏中庙和遗迹我们又该如何触发呢?想必不少玩家还是不了解的,小编整理了三国志11庙和遗迹机制详解,下面一起来看看相关的信息。
三国志11威力加强版庙和遗迹如何触发 三国志11庙和遗迹坐标位置机制详解三国志11威力加强版庙和遗迹如何触发:在三国志11游戏中很多玩法还是挺多的,对于游戏中庙和遗迹我们又该如何触发呢?想必不少玩家还是不了解的,小编整理了三国志11庙和遗迹机制详解,下面一起来看看相关的信息。 -
 学习通如何查看学号工号_学习通查看学号工号方法介绍学习通查看学号工号方法介绍:对于学习通这款软件功能还是挺多的,在这款软件想要查询工号又该如何搞呢?这也是很多用户不了解的,在这里为用户整理了学习通查看工号学号方法介绍,下面一起来看看相关的信息。
学习通如何查看学号工号_学习通查看学号工号方法介绍学习通查看学号工号方法介绍:对于学习通这款软件功能还是挺多的,在这款软件想要查询工号又该如何搞呢?这也是很多用户不了解的,在这里为用户整理了学习通查看工号学号方法介绍,下面一起来看看相关的信息。 -
 学习通如何添加好友_学习通添加好友方法教程学习通添加好友方法教程:在学习通这款软件功能还是挺多的,对于这款软件想和别人聊天又该如何搞呢?这也是很多玩家不了解的,小编整理了学习通添加好友方法介绍,下面一起来看看相关的信息。
学习通如何添加好友_学习通添加好友方法教程学习通添加好友方法教程:在学习通这款软件功能还是挺多的,对于这款软件想和别人聊天又该如何搞呢?这也是很多玩家不了解的,小编整理了学习通添加好友方法介绍,下面一起来看看相关的信息。 -
 uc浏览器收藏如何设置密码_uc浏览器隐私收藏设置方法介绍uc浏览器收藏如何设置密码:对于uc浏览器这款软件想必很多用户都在使用,当然在这款软件隐私收藏如何加密呢?想必很多玩家还是不了解的,小编整理了相关内容介绍,下面一起来看看相关的信息。
uc浏览器收藏如何设置密码_uc浏览器隐私收藏设置方法介绍uc浏览器收藏如何设置密码:对于uc浏览器这款软件想必很多用户都在使用,当然在这款软件隐私收藏如何加密呢?想必很多玩家还是不了解的,小编整理了相关内容介绍,下面一起来看看相关的信息。 -
 Hinova9SE是华为手机吗-hinova9se配置参数处理器Hi nova 9 SE是华为手机吗?这款手机是5G手机,但是华为旗舰机手机也没有支持5G,很多网友想知道Hi nova 9 SE手机和华为什么关系,一起来看看吧
Hinova9SE是华为手机吗-hinova9se配置参数处理器Hi nova 9 SE是华为手机吗?这款手机是5G手机,但是华为旗舰机手机也没有支持5G,很多网友想知道Hi nova 9 SE手机和华为什么关系,一起来看看吧 -
 都市天际线电脑配置推荐城市:天涯线,这款游戏在steam平台、EPIC平台以及某宝都可以买到,游戏本体原价是88元(又有好多免费和付费的DLC后头会给大伙讲),每个平台偶然会打折乃至免
都市天际线电脑配置推荐城市:天涯线,这款游戏在steam平台、EPIC平台以及某宝都可以买到,游戏本体原价是88元(又有好多免费和付费的DLC后头会给大伙讲),每个平台偶然会打折乃至免 -
 ensp怎么保存配置(ensp 保存)1、配置好了一些命令。首先我们要退出用户模式。命令是quit。 2、退出用户模式后输入save。 3、在弹出的输入一行中写一个y,表示yes. 4、等待几秒就可以看到保存成功了。 5、然后我们将配置文件导出。右击
ensp怎么保存配置(ensp 保存)1、配置好了一些命令。首先我们要退出用户模式。命令是quit。 2、退出用户模式后输入save。 3、在弹出的输入一行中写一个y,表示yes. 4、等待几秒就可以看到保存成功了。 5、然后我们将配置文件导出。右击 -
华为Mate40E的参数配置详情,这款手机有着怎么样的性能配置今日,有外媒曝光了关于华为Mate40E的信息,接下来小编就为大家带来了,华为Mate40E的参数配
-
 华为mya-al10什么型号 华为mya-al10配置信息华为mya-al10的手机型号是华为荣耀畅玩6全网通版,是一部性价比比较高的手机。
华为mya-al10什么型号 华为mya-al10配置信息华为mya-al10的手机型号是华为荣耀畅玩6全网通版,是一部性价比比较高的手机。 -
 恶魔秘境0氪多少抽才能全抽奖紫26-0氪全紫抽数计算恶魔秘境氪多少抽才能全抽奖紫26,零氪玩家们想要抽齐全紫26需要2225抽,登录118天=118抽,首通865=865抽,魔晶消费87216约等于1212抽,其他
恶魔秘境0氪多少抽才能全抽奖紫26-0氪全紫抽数计算恶魔秘境氪多少抽才能全抽奖紫26,零氪玩家们想要抽齐全紫26需要2225抽,登录118天=118抽,首通865=865抽,魔晶消费87216约等于1212抽,其他 -
 失业保险金发放标准 失业保险金金额计算方法失业保险金的发放标准和金额计算方法因地因人而异。根据当地最低工资水平以及失业前的平均工资来确定标准。计算时考虑了缴费基数、年限以及失业的原因,同时也需要遵守当地的
失业保险金发放标准 失业保险金金额计算方法失业保险金的发放标准和金额计算方法因地因人而异。根据当地最低工资水平以及失业前的平均工资来确定标准。计算时考虑了缴费基数、年限以及失业的原因,同时也需要遵守当地的 -
 白条取现提前还款还收利息吗?有两种计算方式!轻松看懂白条取现本身就需要支付利息,提前还款时自然也会涉及利息,关键在于是否还有其他手续费。下面我们详细探讨一下:一、白条取现的利息计算方法-按日计息:总利息=借款本金×
白条取现提前还款还收利息吗?有两种计算方式!轻松看懂白条取现本身就需要支付利息,提前还款时自然也会涉及利息,关键在于是否还有其他手续费。下面我们详细探讨一下:一、白条取现的利息计算方法-按日计息:总利息=借款本金× -
这就是江湖刀法枪法主动技能输出怎么计算大家好!今天我要为大家分享的就是关于江湖中刀法枪法主动技能输出的秘密哦!这可是很多玩家都想知道的,现在终于有了解决的方法了呢
-
 “芯片光刻工程师”的工作环境要求是_2025支付宝蚂蚁新村7.14答案最新2025支付宝蚂蚁新村7.14答案最新:支付宝蚂蚁新村今天答题已经更新了,玩家参与答题也能获得相应的奖励。在这里整理了蚂蚁新村7月14日答题“芯片光刻工程师”的工作环境要求是?下面一起来看看相关的信息。
“芯片光刻工程师”的工作环境要求是_2025支付宝蚂蚁新村7.14答案最新2025支付宝蚂蚁新村7.14答案最新:支付宝蚂蚁新村今天答题已经更新了,玩家参与答题也能获得相应的奖励。在这里整理了蚂蚁新村7月14日答题“芯片光刻工程师”的工作环境要求是?下面一起来看看相关的信息。 -
 《守望先锋国服17至18赛季优化竞技环境与玩家互动》守望先锋国服官方近日发布通知,表示将在17至18赛季对游戏进行一系列调整和优化。为进一步净化电竞环境,官方计划采取措施强化对违规行为的管理,优化积分系统,并简化奖
《守望先锋国服17至18赛季优化竞技环境与玩家互动》守望先锋国服官方近日发布通知,表示将在17至18赛季对游戏进行一系列调整和优化。为进一步净化电竞环境,官方计划采取措施强化对违规行为的管理,优化积分系统,并简化奖 -
 就我眼神好流浪月球怎么过-帮助他们改善旅途环境通关攻略就我眼神好流浪月球怎么过?这一关我们必要拖动扳手到必要改良的所在,花光一切扳手。今日手游网小编就为网友带来了就我眼神好流浪月球帮助他们改良旅途处境通关教程,必要的来借鉴一下,期望能够给网友带来帮助。
就我眼神好流浪月球怎么过-帮助他们改善旅途环境通关攻略就我眼神好流浪月球怎么过?这一关我们必要拖动扳手到必要改良的所在,花光一切扳手。今日手游网小编就为网友带来了就我眼神好流浪月球帮助他们改良旅途处境通关教程,必要的来借鉴一下,期望能够给网友带来帮助。 -
 汉字找茬王帮山区孩子改善学习环境怎么过关汉字找茬王帮山区孩子改善学习环境怎么过关?这一关我们需求拖动助学金到需求更改的地点,花光悉数钱。接下来是小编给网友带来的汉字找茬王帮山区孩子革新学习处境通关教程,好奇的玩家们一起来瞧瞧吧。
汉字找茬王帮山区孩子改善学习环境怎么过关汉字找茬王帮山区孩子改善学习环境怎么过关?这一关我们需求拖动助学金到需求更改的地点,花光悉数钱。接下来是小编给网友带来的汉字找茬王帮山区孩子革新学习处境通关教程,好奇的玩家们一起来瞧瞧吧。 -
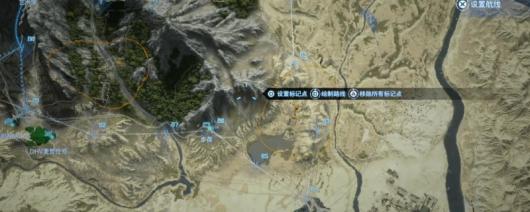 《死亡搁浅2》墨西哥区域滑索搭建路线推荐在死亡搁浅,墨西哥地区的探险之旅充满了挑战和惊喜。由于地形多变且难度大,从一个地方到达另一个需要一定的冒险技能
《死亡搁浅2》墨西哥区域滑索搭建路线推荐在死亡搁浅,墨西哥地区的探险之旅充满了挑战和惊喜。由于地形多变且难度大,从一个地方到达另一个需要一定的冒险技能 -
 荒野起源绿屋建造方法-荒野起源如何搭建绿屋荒野起源作为一款结合了生存、探索、建造和战斗等多种玩法的开放世界游戏,为玩家提供了一个自由且充满挑战的游戏环境。在这片广袤的荒野中,建造一座属于自己的绿屋,不仅是为了生存,更是为了探索这个世界的无限可能。荒野起源绿屋怎么建造在荒野起源中,建造绿屋首先需要玩家选
荒野起源绿屋建造方法-荒野起源如何搭建绿屋荒野起源作为一款结合了生存、探索、建造和战斗等多种玩法的开放世界游戏,为玩家提供了一个自由且充满挑战的游戏环境。在这片广袤的荒野中,建造一座属于自己的绿屋,不仅是为了生存,更是为了探索这个世界的无限可能。荒野起源绿屋怎么建造在荒野起源中,建造绿屋首先需要玩家选