LangExtract 谷歌开源的结构化信息提取工具
时间:2025-08-10 13:02:07
LangExtract 是什么
高效信息提取工具:langextract谷歌推出了一款名为 langextract 的开源 Python 库,旨在从非结构化文本中高效提取结构化信息。该工具依托大型语言模型(LLM),能够自动解析复杂文本如临床记录和技术报告等,并精准识别并结构化关键内容,确保每项提取结果都能在原始文本中找到精确对应的位置。langextract 支持多种 LLM,既兼容云端模型(如 Google Gemini)也支持本地部署的开源模型(通过 Ollama 接口)。它无需对模型进行微调,仅需提供少量示例即可定义提取任务,极大地降低了使用门槛。适用于各类专业领域,包括医疗、法律、技术等领域。langextract 可以显著提高信息提取的速度和准确性,使得专业人士能够快速找到所需的信息,大大提高了工作效率和数据处理的准确度。无论是复杂的医学报告还是工程报告,langextract 都能轻松应对,提供高效且准确的解决方案。
LangExtract 的核心功能
精准源文本定位:将每一项提取结果与原文中的具体位置进行映射,支持可视化高亮显示,便于人工审核与溯源。 结构化输出保障:根据用户提供的样本,强制生成一致的结构化输出格式,提升数据提取的准确性和标准化水平。 长文本高效处理:采用智能文本分块策略、并行计算和多轮提取机制,有效应对大篇幅文档,增强信息召回能力。 交互式审查界面:生成可交互的 HTML 可视化报告,帮助用户在原始上下文中快速浏览和验证成千上万条提取结果。 多模型灵活集成:支持多种大型语言模型,包括 Google Gemini 等云服务模型,以及通过 Ollama 接入的本地开源模型。 跨领域快速适配:仅需提供少量任务示例,无需模型训练或微调,即可快速应用于医疗、法律、金融等不同领域。 利用 LLM 的先验知识:通过精心设计的提示词和示例,引导语言模型调用其内在知识,实现更智能、上下文敏感的信息提取。
LangExtract 的技术实现原理
基于大型语言模型(LLM):LangExtract 革新的文本处理方案使用预训练的大型语言模型(如 Gemini 或 GPT 系列),LangExtract 深入理解文本内容,并根据用户的定制化提示和示例生成结构化的输出。其在推理阶段直接完成信息抽取,无需额外的训练过程。针对长文档,系统将文本划分为多个逻辑块以提升处理效率。通过并行机制同时处理多个文本块,大大缩短了整体处理时间。此外,为了确保关键信息不被遗漏,LangExtract 实施了多轮提取机制。每一轮聚焦于不同的文本区域或信息类型,从而提高了覆盖率和召回率。为了增强结果的可信度,每次的提取结果都会记录其原文中的起止位置,并结合高亮展示功能帮助用户验证提取的准确性。这种精确的位置映射不仅实现了可追溯性,还便于用户更好地理解抽取内容来源及其含义。
LangExtract 的项目资源
官方 PyPI 页面:https://www.php.cn/link/56c9807aabbf7dc7279c1ec2b314bc47 GitHub 开源仓库:https://www.php.cn/link/bbd2f7ac63dcd6415a821f8b0168b88e
LangExtract 的典型应用场景
医疗健康领域:自动从电子病历和医生笔记中提取患者的详细病史、诊断结果、用药记录等结构化信息,助力临床研究和数据分析工作。法律文书处理:快速识别合同中的责任条款、有效期、金额等内容,支持律师高效审核大量法律文件。金融分析:从财报、审计报告或交易日志中抽取财务指标、风险事件等关键数据,用于合规监控与投资决策的辅助。科研信息提取:从学术论文中提炼实验设计、研究结果及图表数据,帮助研究人员进行系统性综述和知识图谱构建。企业文档自动化:自动提取发票、订单、调研报告等商业文件中的关键字段,提高办公自动化和数据录入效率。
以上就是LangExtract 谷歌开源的结构化信息提取工具的详细内容,更多请关注其它相关文章!
热门推荐
-
 LangExtract 谷歌开源的结构化信息提取工具LangExtract是什么高效信息提取工具:langextract谷歌推出了一款名为langextract的开源Python库,旨在从非结构化文本中高效提取结构
LangExtract 谷歌开源的结构化信息提取工具LangExtract是什么高效信息提取工具:langextract谷歌推出了一款名为langextract的开源Python库,旨在从非结构化文本中高效提取结构 -
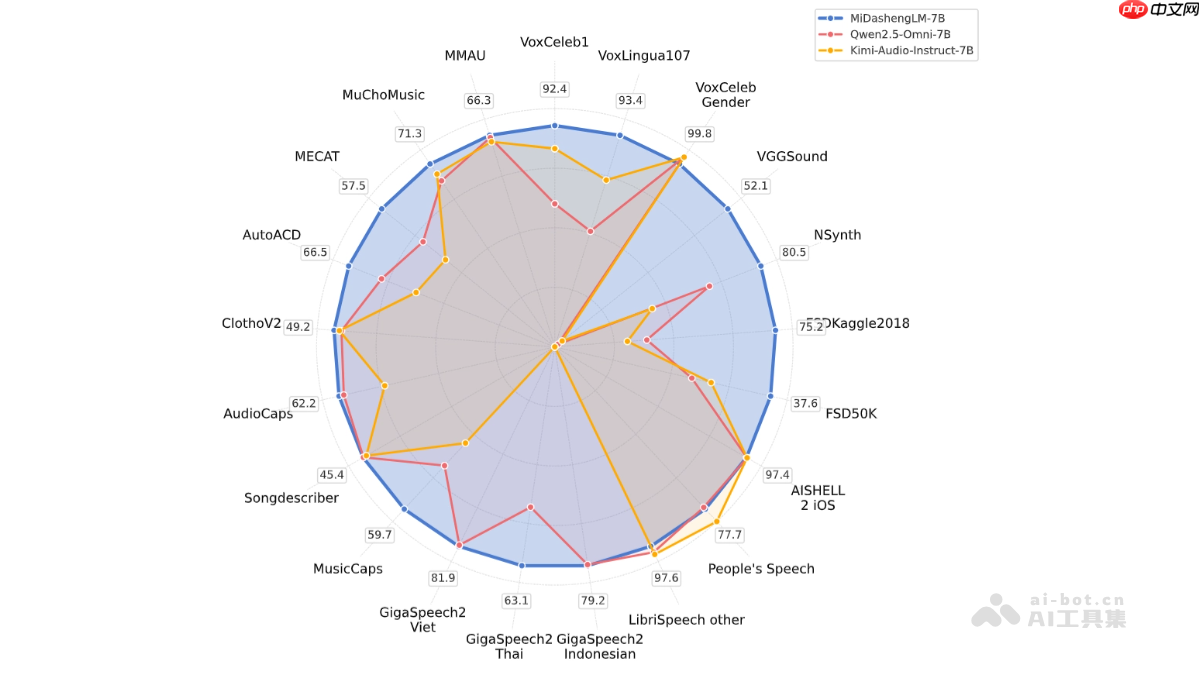 MiDashengLM 小米开源的高效声音理解大模型MiDashengLM是什么小米推出了一款高效的音频理解大模型:midashenglm-。这款模型是由xiaomidasheng音频编码器和qwenomni-th
MiDashengLM 小米开源的高效声音理解大模型MiDashengLM是什么小米推出了一款高效的音频理解大模型:midashenglm-。这款模型是由xiaomidasheng音频编码器和qwenomni-th -
 小米声音理解大模型 MiDashengLM-7B 发布并全量开源,22 个公开评测集刷新最好成绩xiayx8月4日消息,小米自研声音理解大模型MiDashengLM-7B今日正式发布,并全量开源。据小米官方介绍,MiDashengLM-在速度与精度方面实现了
小米声音理解大模型 MiDashengLM-7B 发布并全量开源,22 个公开评测集刷新最好成绩xiayx8月4日消息,小米自研声音理解大模型MiDashengLM-7B今日正式发布,并全量开源。据小米官方介绍,MiDashengLM-在速度与精度方面实现了 -
![FLUX.1 Krea [dev] 黑森林联合Krea AI开源的文生图模型](https://img.php.cn/upload/article/001/246/273/175420057355331.png) FLUX.1 Krea [dev] 黑森林联合Krea AI开源的文生图模型FLUX.1Krea[dev]是什么flux.krea[dev]是由黑森林实验室联合KreaAI共同开发的新一代文本生成图像模型
FLUX.1 Krea [dev] 黑森林联合Krea AI开源的文生图模型FLUX.1Krea[dev]是什么flux.krea[dev]是由黑森林实验室联合KreaAI共同开发的新一代文本生成图像模型 -
 开源电子原型平台arduino起源于开源电子原型平台arduino起源于意大利。arduino是一款便捷灵活、方便上手的开源电子原型平台。arduino构建于开放原始码simple I/O介面版,并且具有使用类似Java、C语言的Processing/Wiring开发环境。
开源电子原型平台arduino起源于开源电子原型平台arduino起源于意大利。arduino是一款便捷灵活、方便上手的开源电子原型平台。arduino构建于开放原始码simple I/O介面版,并且具有使用类似Java、C语言的Processing/Wiring开发环境。 -
 幕布 AI 整理思维脑图?层级结构与重点突出技巧利用幕布AI快速生成思维导图的步骤如下:首先,在幕布中输入、粘贴或导入文本;AI系统会自动分析结构并生成导图,突出关键词与层级关系
幕布 AI 整理思维脑图?层级结构与重点突出技巧利用幕布AI快速生成思维导图的步骤如下:首先,在幕布中输入、粘贴或导入文本;AI系统会自动分析结构并生成导图,突出关键词与层级关系 -
 DeepSeek生成AI讲书稿全过程示范,附生成结构模板要让ai生成高质量讲书稿,关键在于提示清晰、结构明确。一、确定核心目标,如面向职场人士、强调自我认知与学习方法;二、提供通用结构模板,包括开篇引入、核心观点1与2
DeepSeek生成AI讲书稿全过程示范,附生成结构模板要让ai生成高质量讲书稿,关键在于提示清晰、结构明确。一、确定核心目标,如面向职场人士、强调自我认知与学习方法;二、提供通用结构模板,包括开篇引入、核心观点1与2 -
 如何用豆包AI生成带结构的数据内容 豆包AI表格与报告输出方案要让豆包AI生成结构化内容的关键在于精细化指令和格式锁定。以下是详细的步骤:明确需求:首先确定你需要的列名、数据类型以及行数等基本信息
如何用豆包AI生成带结构的数据内容 豆包AI表格与报告输出方案要让豆包AI生成结构化内容的关键在于精细化指令和格式锁定。以下是详细的步骤:明确需求:首先确定你需要的列名、数据类型以及行数等基本信息 -
 中国古建筑榫卯结构属于哪类非遗_2025支付宝蚂蚁新村7.24答案最新2025支付宝蚂蚁新村7.24答案最新:蚂蚁新村今天答题更新了,届时参与答题也能获得相应的奖励。小编整理了蚂蚁新村7月24日答题中国古建筑榫卯结构属于哪类非遗?下面一起来看看相关的信息。
中国古建筑榫卯结构属于哪类非遗_2025支付宝蚂蚁新村7.24答案最新2025支付宝蚂蚁新村7.24答案最新:蚂蚁新村今天答题更新了,届时参与答题也能获得相应的奖励。小编整理了蚂蚁新村7月24日答题中国古建筑榫卯结构属于哪类非遗?下面一起来看看相关的信息。 -
 《大航海探险物语》人物推荐 S级人物信息盘点尝试过大航海探险物语的网友们肯定对游戏之中的人物系统不生疏,人物在游戏之中也是分等级和品阶的。角色的品阶越高,那么他的原始属性一定也就越好
《大航海探险物语》人物推荐 S级人物信息盘点尝试过大航海探险物语的网友们肯定对游戏之中的人物系统不生疏,人物在游戏之中也是分等级和品阶的。角色的品阶越高,那么他的原始属性一定也就越好 -
 抖音聊天信息自动撤回怎么设置在抖音软件和挚友聊天的时刻,有的新闻只想让挚友看一次而后就让新闻主动撤退我们要何如设置呢?目前就和小编来看一下抖音聊天新闻主动撤退设置攻略吧
抖音聊天信息自动撤回怎么设置在抖音软件和挚友聊天的时刻,有的新闻只想让挚友看一次而后就让新闻主动撤退我们要何如设置呢?目前就和小编来看一下抖音聊天新闻主动撤退设置攻略吧 -
 dnf助手查看别人角色信息方法在dnf助手绑定账号添加了角色以后,我们就能够看到自个账号的角色新闻等有关财富了。那么若是我们想要查看别人的角色新闻该怎样弄呢?接下来小编就为网友带来了切实其实的查问教程讲解,不知道的玩家能够跟小编一起来探询下哦!
dnf助手查看别人角色信息方法在dnf助手绑定账号添加了角色以后,我们就能够看到自个账号的角色新闻等有关财富了。那么若是我们想要查看别人的角色新闻该怎样弄呢?接下来小编就为网友带来了切实其实的查问教程讲解,不知道的玩家能够跟小编一起来探询下哦! -
 鄂汇办无有效参保信息解决办法在鄂汇办平台办理医保社保干系服务的时刻,有的玩家会呈现“无有用参保立案新闻”相像的提醒。那么鄂汇办显示无有用参保立案新闻怎么办呢?接下来小编就为网友带来了无有用参保新闻的解决办法讲解,但愿对网友有所帮助。
鄂汇办无有效参保信息解决办法在鄂汇办平台办理医保社保干系服务的时刻,有的玩家会呈现“无有用参保立案新闻”相像的提醒。那么鄂汇办显示无有用参保立案新闻怎么办呢?接下来小编就为网友带来了无有用参保新闻的解决办法讲解,但愿对网友有所帮助。 -
 已作为垃圾信息送达能收到吗 已作为垃圾信息送达能收到吗短信已作为垃圾信息送达能收到,但不会在对方的正常信息栏显示,会显示在屏蔽信息中。如果对方能打开屏蔽信息栏,就能看到你发的信息。但如果对方不打开,就不会看到,手机系统会作为垃圾信息保留一段时间之后予以删除。
已作为垃圾信息送达能收到吗 已作为垃圾信息送达能收到吗短信已作为垃圾信息送达能收到,但不会在对方的正常信息栏显示,会显示在屏蔽信息中。如果对方能打开屏蔽信息栏,就能看到你发的信息。但如果对方不打开,就不会看到,手机系统会作为垃圾信息保留一段时间之后予以删除。 -
 百度网盘分享链接和提取码教程在数字化时代,百度网盘作为一款广受欢迎的云存储工具,为用户提供了便捷的数据存储和分享功能。不论是个人用户还是企业用户,都能通过百度网盘轻松存储、管理和分享文件
百度网盘分享链接和提取码教程在数字化时代,百度网盘作为一款广受欢迎的云存储工具,为用户提供了便捷的数据存储和分享功能。不论是个人用户还是企业用户,都能通过百度网盘轻松存储、管理和分享文件 -
 夸克扫描王怎么提取电子章在夸克扫描王这款应用中,一个备受青睐的功能就是提取印章。这是一项极具实用性的工作工具,专为快速高效地从文档中精准辨识并提取印章而设计
夸克扫描王怎么提取电子章在夸克扫描王这款应用中,一个备受青睐的功能就是提取印章。这是一项极具实用性的工作工具,专为快速高效地从文档中精准辨识并提取印章而设计 -
 百度网盘提取码在哪里输入百度网盘软件中我们能够使用的功能有好多,有好多的网友比较好奇百度网盘索取码在哪里输入呢?而今就来看一下小编给网友带来的百度网盘索取码输入方法吧
百度网盘提取码在哪里输入百度网盘软件中我们能够使用的功能有好多,有好多的网友比较好奇百度网盘索取码在哪里输入呢?而今就来看一下小编给网友带来的百度网盘索取码输入方法吧 -
 medibang paint渐变工具位置在哪-medibang paint渐变工具在哪里找在medibangpaint软件中,渐变工具是创作多彩画面的得力助手。它能为作品增添丰富的色彩过渡效果,让画面更加生动和富有层次感。那么,medibangpaint渐变工具究竟在哪里呢?接下来为你详细介绍。打开medibangpaint软件首先,确保你已成功安
medibang paint渐变工具位置在哪-medibang paint渐变工具在哪里找在medibangpaint软件中,渐变工具是创作多彩画面的得力助手。它能为作品增添丰富的色彩过渡效果,让画面更加生动和富有层次感。那么,medibangpaint渐变工具究竟在哪里呢?接下来为你详细介绍。打开medibangpaint软件首先,确保你已成功安 -
 不会编程也能用!AI工具使用方法全流程详解在零基础用户探索AI工具时,首要考虑的是图形化界面、操作简便且提供详细教程和社区支持的平台。首先明确自己的AI需求,比如是图片生成还是数据分析?接着,查阅其他用户
不会编程也能用!AI工具使用方法全流程详解在零基础用户探索AI工具时,首要考虑的是图形化界面、操作简便且提供详细教程和社区支持的平台。首先明确自己的AI需求,比如是图片生成还是数据分析?接着,查阅其他用户 -
 怎样让 AI 模型数据备份工具与豆包配合备份数据?实用教程使用AI模型通过豆包进行数据备份的方法涉及以下几个步骤:确认工具兼容性:首先,要确定所选的备份工具是否支持通过豆包接口协议实现数据备份功能,并检查其是否有提供AP
怎样让 AI 模型数据备份工具与豆包配合备份数据?实用教程使用AI模型通过豆包进行数据备份的方法涉及以下几个步骤:确认工具兼容性:首先,要确定所选的备份工具是否支持通过豆包接口协议实现数据备份功能,并检查其是否有提供AP -
 OpenAI 教育负责人呼吁:学生应将 ChatGPT 视为工具而非“答题机器”,据商业内幕的最新报道,OpenAI教育副总裁LeahBelsky指出,在以人工智能主导的新时代背景下,那些试图抵制或阻碍技术进步的个人将失去竞争优势
OpenAI 教育负责人呼吁:学生应将 ChatGPT 视为工具而非“答题机器”,据商业内幕的最新报道,OpenAI教育副总裁LeahBelsky指出,在以人工智能主导的新时代背景下,那些试图抵制或阻碍技术进步的个人将失去竞争优势